Кодирование информации. Двоичное кодирование
Двоичный код - это подача информации путем сочетания символов 0 или 1. Порою бывает очень сложно понять принцип кодирования информации в виде этих двух чисел, однако мы постараемся все подробно разъяснить.
Кстати, на нашем сайте вы можете перевести любой текст в десятичный, шестнадцатеричный, двоичный код воспользовавшись Калькулятором кодов онлайн .
Видя что-то впервые, мы зачастую задаемся логичным вопросом о том, как это работает. Любая новая информация воспринимается нами, как что-то сложное или созданное исключительно для разглядываний издали, однако для людей, желающих узнать подробнее о двоичном коде , открывается незамысловатая истина - бинарный код вовсе не сложный для понимания, как нам кажется. К примеру, английская буква T в двоичной системе приобретет такой вид - 01010100, E - 01000101 и буква X - 01011000. Исходя из этого, понимаем, что английское слово TEXT в виде двоичного кода будет выглядеть таким вот образом: 01010100 01000101 01011000 01010100. Компьютер понимает именно такое изложение символов для данного слова, ну а мы предпочитаем видеть его в изложении букв алфавита.
На сегодняшний день двоичный код активно используется в программировании, поскольку работают вычислительные машины именно благодаря ему. Но программирование не свелось до бесконечного набора нулей и единиц. Поскольку это достаточно трудоемкий процесс, были приняты меры для упрощения понимания между компьютером и человеком. Решением проблемы послужило создание языков программирования (бейсик, си++ и т.п.). В итоге программист пишет программу на языке, который он понимает, а потом программа-компилятор переводит все в машинный код, запуская работу компьютера.
Перевод натурального числа десятичной системы счисления в двоичную систему.
Чтобы перевести числа из десятичной системы счисления в двоичную пользуются "алгоритмом замещения", состоящим из такой последовательности действий:
1. Выбираем нужное число и делим его на 2. Если результат деления получился с остатком, то число двоичного кода будет 1, если остатка нет - 0.
2. Откидывая остаток, если он есть, снова делим число, полученное в результате первого деления, на 2. Устанавливаем число двоичной системы в зависимости от наличия остатка.
3. Продолжаем делить, вычисляя число двоичной системы из остатка, до тех пор, пока не дойдем до числа, которое делить нельзя - 0.
4. В этот момент считается, что двоичный код готов.
Для примера переведем в двоичную систему число 7:
1. 7: 2 = 3.5. Поскольку остаток есть, записываем первым числом двоичного кода 1.
2. 3: 2 = 1.5. Повторяем процедуру с выбором числа кода между 1 и 0 в зависимости от остатка.
3. 1: 2 = 0.5. Снова выбираем 1 по тому же принципу.
4. В результате получаем, переведенный из десятичной системы счисления в двоичную, код - 111.
Таким образом можно переводить бесконечное множество чисел. Теперь попробуем сделать наоборот - перевести число из двоичной в десятичную.
Перевод числа двоичной системы в десятичную.
Для этого нам нужно пронумеровать наше двоичное число 111 с конца, начиная нулем. Для 111 это 1^2 1^1 1^0. Исходя из этого, номер для числа послужит его степенем. Далее выполняем действия по формуле: (x * 2^y) + (x * 2^y) + (x * 2^y), где x - порядковое число двоичного кода, а y - степень этого числа. Подставляем наше двоичное число под эту формулу и считаем результат. Получаем: (1 * 2^2) + (1 * 2^1) + (1 * 2^0) = 4 + 2 + 1 = 7.
Немного из истории двоичной системы счисления.
Принято считать, что впервые двоичную систему предложил Готфрид Вильгельм Лейбниц, который считал систему полезной в сложных математических вычислениях и науке. Но по неким данным, до его предложения о двоичной системе счисления, в Китае появилась настенная надпись, которая расшифровывалась при использовании двоичного кода . На надписи были изображены длинные и короткие палочки. Предполагая, что длинная это 1, а короткая палочка - 0, есть доля вероятности, что в Китае идея двоичного кода существовала многим ранее его официального открытия. Расшифровка кода определила там только простое натуральное число, однако это факт, который им и остается.
08. 06.2018
Блог Дмитрия Вассиярова.
Двоичный код — где и как применяется?
Сегодня я по-особому рад своей встрече с вами, дорогие мои читатели, ведь я чувствую себя учителем, который на самом первом уроке начинает знакомить класс с буквами и цифрами. А поскольку мы живем в мире цифровых технологий, то я расскажу вам, что такое двоичный код, являющийся их основой.

Начнем с терминологии и выясним, что означит двоичный. Для пояснения вернемся к привычному нам исчислению, которое называется «десятичным». То есть, мы используем 10 знаков-цифр, которые дают возможность удобно оперировать различными числами и вести соответствующую запись.
Следуя этой логике, двоичная система предусматривает использование только двух знаков. В нашем случае, это всего лишь «0» (ноль) и «1» единица. И здесь я хочу вас предупредить, что гипотетически на их месте могли бы быть и другие условные обозначения, но именно такие значения, обозначающие отсутствие (0, пусто) и наличие сигнала (1 или «палочка»), помогут нам в дальнейшем уяснить структуру двоичного кода.
Зачем нужен двоичный код?
До появления ЭВМ использовались различные автоматические системы, принцип работы которых основан на получении сигнала. Срабатывает датчик, цепь замыкается и включается определенное устройство. Нет тока в сигнальной цепи – нет и срабатывания. Именно электронные устройства позволили добиться прогресса в обработке информации, представленной наличием или отсутствием напряжения в цепи.

Дальнейшее их усложнение привело к появлению первых процессоров, которые так же выполняли свою работу, обрабатывая уже сигнал, состоящий из импульсов, чередующихся определенным образом. Мы сейчас не будем вникать в программные подробности, но для нас важно следующее: электронные устройства оказались способными различать заданную последовательность поступающих сигналов. Конечно, можно и так описать условную комбинацию: «есть сигнал»; «нет сигнала»; «есть сигнал»; «есть сигнал». Даже можно упростить запись: «есть»; «нет»; «есть»; «есть».
Но намного проще обозначить наличие сигнала единицей «1», а его отсутствие – нулем «0». Тогда мы вместо всего этого сможем использовать простой и лаконичный двоичный код: 1011.
Безусловно, процессорная техника шагнула далеко вперед и сейчас чипы способны воспринимать не просто последовательность сигналов, а целые программы, записанные определенными командами, состоящими из отдельных символов.
Но для их записи используется все тот же двоичный код, состоящий из нулей и единиц, соответствующий наличию или отсутствию сигнала. Есть он, или его нет – без разницы. Для чипа любой из этих вариантов – это единичная частичка информации, которая получила название «бит» (bit — официальная единица измерения).
Условно, символ можно закодировать последовательностью из нескольких знаков. Двумя сигналами (или их отсутствием) можно описать всего четыре варианта: 00; 01;10; 11. Такой способ кодирования называется двухбитным. Но он может быть и:
- Четырехбитным (как в примере на абзац выше 1011) позволяет записать 2^4 = 16 комбинаций-символов;
- Восьмибитным (например: 0101 0011; 0111 0001). Одно время он представлял наибольший интерес для программирования, поскольку охватывал 2^8 = 256 значений. Это давало возможность описать все десятичные цифры, латинский алфавит и специальные знаки;
- Шестнадцатибитным (1100 1001 0110 1010) и выше. Но записи с такой длинной – это уже для современных более сложных задач. Современные процессоры используют 32-х и 64-х битную архитектуру;
Скажу честно, единой официальной версии нет, то так сложилось, что именно комбинация из восьми знаков стала стандартной мерой хранящейся информации, именуемой «байт». Таковая могла применяться даже к одной букве, записанной 8-и битным двоичным кодом. Итак, дорогие мои друзья, запомните пожалуйста (если кто не знал):
8 бит = 1 байт.

Так принято. Хотя символ, записанный 2-х или 32-х битным значением так же номинально можно назвать байтом. Кстати, благодаря двоичному коду мы можем оценивать объемы файлов, измеряемые в байтах и скорость передачи информации и интернета (бит в секунду).
Бинарная кодировка в действии
Для стандартизации записи информации для компьютеров было разработано несколько кодировочных систем, одна из которых ASCII, базирующаяся на 8-и битной записи, получила широкое распространение. Значения в ней распределены особым образом:
- первый 31 символ – управляющие (с 00000000 по 00011111). Служат для служебных команд, вывода на принтер или экран, звуковых сигналов, форматирования текста;
- следующие с 32 по 127 (00100000 – 01111111) латинский алфавит и вспомогательные символы и знаки препинания;
- остальные, до 255-го (10000000 – 11111111) – альтернативная, часть таблицы для специальных задач и отображения национальных алфавитов;
Расшифровка значений в ней показано в таблице.

Если вы считаете, что «0» и «1» расположены в хаотичном порядке, то глубоко ошибаетесь. На примере любого числа я вам покажу закономерность и научу читать цифры, записанные двоичным кодом. Но для этого примем некоторые условности:
- Байт из 8 знаков будем читать справа налево;
- Если в обычных числах у нас используются разряды единиц, десятков, сотен, то здесь (читая в обратном порядке) для каждого бита представлены различные степени «двойки»: 256-124-64-32-16-8- 4-2-1;
- Теперь смотрим на двоичный код числа, например 00011011. Там, где в соответствующей позиции есть сигнал «1» – берем значения этого разряда и суммируем их привычным способом. Соответственно: 0+0+0+32+16+0+2+1 = 51. В правильности данного метода вы можете убедиться, взглянув на таблицу кодов.

Теперь, мои любознательные друзья, вы не только знаете что такое двоичный код, но и умеете преобразовать зашифрованную им информацию.
Язык, понятный современной технике
Конечно, алгоритм считывания двоичного кода процессорными устройствами намного сложнее. Но зато его помощью можно записать все что угодно:
- Текстовую информацию с параметрами форматирования;
- Числа и любые операции с ними;
- Графические и видео изображения;
- Звуки, в том числе и выходящие и за предел нашей слышимости;
Помимо этого, благодаря простоте «изложения» возможны различные способы записи бинарной информации:
Дополняет преимущества двоичного кодирования практически неограниченные возможности по передаче информации на любые расстояния. Именно такой способ связи используется с космическими кораблями и искусственными спутниками.
Так что, сегодня двоичная система счисления является языком, понятным большинству используемых нами электронных устройств. И что самое интересное, никакой другой альтернативы для него пока не предвидится.

Думаю, что изложенной мною информации для начала вам будет вполне достаточно. А дальше, если возникнет такая потребность, каждый сможет углубиться в самостоятельное изучение этой темы.
Я же буду прощаться и после небольшого перерыва подготовлю для вас новую статью моего блога, на какую-нибудь интересную тему.
Лучше, если вы сами ее мне подскажите;)
До скорых встреч.
Компьютеры не понимают слов и цифр так, как это делают люди. Современное программное обеспечение позволяет конечному пользователю игнорировать это, но на самых низких уровнях ваш компьютер оперирует двоичным электрическим сигналом, который имеет только два состояния : есть ток или нет тока. Чтобы «понять» сложные данные, ваш компьютер должен закодировать их в двоичном формате.
Двоичная система основывается на двух цифрах – 1 и 0, соответствующим состояниям включения и выключения, которые ваш компьютер может понять. Вероятно, вы знакомы с десятичной системой. Она использует десять цифр – от 0 до 9, а затем переходит к следующему порядку, чтобы сформировать двузначные числа, причем цифра из каждого следующего порядка в десять раз больше, чем предыдущая. Двоичная система аналогична, причем каждая цифра в два раза больше, чем предыдущая.
Подсчет в двоичном формате
В двоичном выражении первая цифра равноценна 1 из десятичной системы. Вторая цифра равна 2, третья – 4, четвертая – 8, и так далее – удваивается каждый раз. Добавление всех этих значений даст вам число в десятичном формате.
1111 (в двоичном формате) = 8 + 4 + 2 + 1 = 15 (в десятичной системе)
Учет 0 даёт нам 16 возможных значений для четырех двоичных битов. Переместитесь на 8 бит, и вы получите 256 возможных значений. Это занимает намного больше места для представления, поскольку четыре цифры в десятичной форме дают нам 10000 возможных значений. Конечно, бинарный код занимает больше места, но компьютеры понимают двоичные файлы намного лучше, чем десятичную систему. И для некоторых вещей, таких как логическая обработка, двоичный код лучше десятичного.
Следует сказать, что существует ещё одна базовая система, которая используется в программировании: шестнадцатеричная . Хотя компьютеры не работают в шестнадцатеричном формате, программисты используют её для представления двоичных адресов в удобочитаемом формате при написании кода. Это связано с тем, что две цифры шестнадцатеричного числа могут представлять собой целый байт, то есть заменяют восемь цифр в двоичном формате. Шестнадцатеричная система использует цифры 0-9, а также буквы от A до F, чтобы получить дополнительные шесть цифр.
Почему компьютеры используют двоичные файлы
Короткий ответ: аппаратное обеспечение и законы физики. Каждый символ в вашем компьютере является электрическим сигналом, и в первые дни вычислений измерять электрические сигналы было намного сложнее. Было более разумно различать только «включенное» состояние, представленное отрицательным зарядом, и «выключенное» состояние, представленное положительным зарядом.
Для тех, кто не знает, почему «выключено» представлено положительным зарядом, это связано с тем, что электроны имеют отрицательный заряд, а больше электронов – больше тока с отрицательным зарядом.
Таким образом, ранние компьютеры размером с комнату использовали двоичные файлы для создания своих систем, и хотя они использовали более старое, более громоздкое оборудование, они работали на тех же фундаментальных принципах. Современные компьютеры используют, так называемый, транзистор для выполнения расчетов с двоичным кодом.
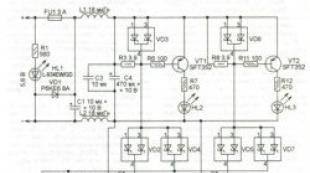
Вот схема типичного транзистора:

По сути, он позволяет току течь от источника к стоку, если в воротах есть ток. Это формирует двоичный ключ. Производители могут создавать эти транзисторы невероятно малыми – вплоть до 5 нанометров или размером с две нити ДНК. Это то, как работают современные процессоры, и даже они могут страдать от проблем с различением включенного и выключенного состояния (хотя это связано с их нереальным молекулярным размером, подверженным странностям квантовой механики ).
Почему только двоичная система
Поэтому вы можете подумать: «Почему только 0 и 1? Почему бы не добавить ещё одну цифру?». Хотя отчасти это связано с традициями создания компьютеров, вместе с тем, добавление ещё одной цифры означало бы необходимость выделять ещё одно состояние тока, а не только «выключен» или «включен».
Проблема здесь в том, что если вы хотите использовать несколько уровней напряжения, вам нужен способ легко выполнять вычисления с ними, а современное аппаратное обеспечение, способное на это, не жизнеспособно как замена двоичных вычислений. Например, существует, так называемый, тройной компьютер , разработанный в 1950-х годах, но разработка на том и прекратилась. Тернарная логика более эффективна, чем двоичная, но пока ещё нет эффективной замены бинарного транзистора или, по крайней мере, нет транзистора столь же крошечных масштабов, что и двоичные.
Причина, по которой мы не можем использовать тройную логику, сводится к тому, как транзисторы соединяются в компьютере и как они используются для математических вычислений. Транзистор получает информацию на два входа, выполняет операцию и возвращает результат на один выход.
Таким образом, бинарная математика проще для компьютера, чем что-либо ещё. Двоичная логика легко преобразуется в двоичные системы, причем True и False соответствуют состояниям Вкл и Выкл .

Бинарная таблица истинности, работающая на двоичной логике, будет иметь четыре возможных выхода для каждой фундаментальной операции. Но, поскольку тройные ворота используют три входа, тройная таблица истинности имела бы 9 или более. В то время как бинарная система имеет 16 возможных операторов (2^2^2), троичная система имела бы 19683 (3^3^3). Масштабирование становится проблемой, поскольку, хотя троичность более эффективна, она также экспоненциально более сложна.
Кто знает? В будущем мы вполне возможно увидим тройничные компьютеры, поскольку бинарная логика столкнулась с проблемами миниатюризации. Пока же мир будет продолжать работать в двоичном режиме.
Разрядность двоичного кода, Преобразование информации из непрерывной формы в дискретную, Универсальность двоичного кодирования, Равномерные и неравномерные коды, Информатика 7 класс Босова, Информатика 7 класс
1.5.1. Преобразование информации из непрерывной формы в дискретную
Для решения своих задач человеку часто приходится преобразовывать имеющуюся информацию из одной формы представления в другую. Например, при чтении вслух происходит преобразование информации из дискретной (текстовой) формы в непрерывную (звук). Во время диктанта на уроке русского языка, наоборот, происходит преобразование информации из непрерывной формы (голос учителя) в дискретную (записи учеников).
Информация, представленная в дискретной форме, значительно проще для передачи, хранения или автоматической обработки. Поэтому в компьютерной технике большое внимание уделяется методам преобразования информации из непрерывной формы в дискретную.
Дискретизация информации - процесс преобразования информации из непрерывной формы представления в дискретную.
Рассмотрим суть процесса дискретизации информации на примере.
На метеорологических станциях имеются самопишущие приборы для непрерывной записи атмосферного давления . Результатом их работы являются барограммы - кривые, показывающие, как изменялось давление в течение длительных промежутков времени. Одна из таких кривых, вычерченная прибором в течение семи часов проведения наблюдений, показана на рис. 1.9.
На основании полученной информации можно построить таблицу, содержащую показания прибора в начале измерений и на конец каждого часа наблюдений (рис. 1.10).
Полученная таблица даёт не совсем полную картину того, как изменялось давление за время наблюдений: например, не указано самое большое значение давления, имевшее место в течение четвёртого часа наблюдений. Но если занести в таблицу значения давления, наблюдаемые каждые полчаса или 15 минут, то новая таблица будет давать более полное представление о том, как изменялось давление.
Таким образом, информацию, представленную в непрерывной форме (барограмму, кривую), мы с некоторой потерей точности преобразовали в дискретную форму (таблицу).
В дальнейшем вы познакомитесь со способами дискретного представления звуковой и графической информации.
Цепочки из трёх двоичных символов получаются дополнением двухразрядных двоичных кодов справа символом 0 или 1. В итоге кодовых комбинаций из трёх двоичных символов получается 8 - вдвое больше, чем из двух двоичных символов:
Соответственно, четырёхразрядйый двоичный позволяет получить 16 кодовых комбинаций, пятиразрядный - 32, шестиразрядный - 64 и т. д. Длину двоичной цепочки - количество символов в двоичном коде - называют разрядностью двоичного кода.
Обратите внимание, что:
4 = 2 * 2,
8 = 2 * 2 * 2,
16 = 2 * 2 * 2 * 2,
32 = 2 * 2 * 2 * 2 * 2 и т. д.
Здесь количество кодовых комбинаций представляет собой произведение некоторого количества одинаковых множителей, равного разрядности двоичного кода.
Если количество кодовых комбинаций обозначить буквой N, а разрядность двоичного кода - буквой i, то выявленная закономерность в общем виде будет записана так:
N = 2 * 2 * ... * 2.
i множителей
В математике такие произведения записывают в виде:
N = 2 i .
Запись 2 i читают так: «2 в i-й степени».
Задача. Вождь племени Мульти поручил своему министру разработать двоичный и перевести в него всю важную информацию . Двоичный какой разрядности потребуется, если алфавит, используемый племенем Мульти, содержит 16 символов? Выпишите все кодовые комбинации.
Решение. Так как алфавит племени Мульти состоит из 16 символов, то и кодовых комбинаций им нужно 16. В этом случае длина (разрядность) двоичного кода определяется из соотношения: 16 = 2 i . Отсюда i = 4.
Чтобы выписать все кодовые комбинации из четырёх 0 и 1, воспользуемся схемой на рис. 1.13: 0000, 0001, 0010, 0011, 0100, 0101, 0110,0111,1000,1001,1010,1011,1100,1101,1110,1111.
1.5.3. Универсальность двоичного кодирования
В начале этого параграфа вы узнали, что, представленная в непрерывной форме, может быть выражена с помощью символов некоторого естественного или формального языка. В свою очередь, символы произвольного алфавита могут быть преобразованы в двоичный. Таким образом, с помощью двоичного кода может быть представлена любая на естественных и формальных языках, а также изображения и звуки (рис. 1.14). Это и означает универсальность двоичного кодирования.
Двоичные коды широко используются в компьютерной технике, требуя только двух состояний электронной схемы - «включено» (это соответствует цифре 1) и «выключено» (это соответствует цифре 0).
Простота технической реализации - главное достоинство двоичного кодирования. Недостаток двоичного кодирования - большая длина получаемого кода.
1.5.4. Равномерные и неравномерные коды
Различают равномерные и неравномерные коды. Равномерные коды в кодовых комбинациях содержат одинаковое число символов, неравномерные - разное.
Выше мы рассмотрели равномерные двоичные коды.
Примером неравномерного кода может служить азбука Морзе, в которой для каждой буквы и цифры определена последовательность коротких и длинных сигналов. Так, букве Е соответствует короткий сигнал («точка»), а букве Ш - четыре длинных сигнала (четыре «тире»). Неравномерное позволяет повысить скорость передачи сообщений за счёт того, что наиболее часто встречающиеся в передаваемой информации символы имеют самые короткие кодовые комбинации.
Информация, которую дает этот символ, равна энтропии системы и максимальна в случае, когда оба состояния равновероятны; в этом случае элементарный символ передает информацию 1 (дв. ед.). Поэтому основой оптимального кодирования будет требование, чтобы элементарные символы в закодированном тексте встречались в среднем одинаково часто.
Изложим здесь способ построения кода, удовлетворяющего поставленному условию; этот способ известен под названием «кода Шеннона - Фэно». Идея его состоит в том, что кодируемые символы (буквы или комбинации букв) разделяются на две приблизительно равновероятные группы: для первой группы символов на первом месте комбинации ставится 0 (первый знак двоичного числа, изображающего символ); для второй группы - 1. Далее каждая группа снова делится на две приблизительно равновероятные подгруппы; для символов первой подгруппы на втором месте ставится нуль; для второй подгруппы - единица и т. д.
Продемонстрируем принцип построения кода Шеннона - Фэно на материале русского алфавита (табл. 18.8.1). Отсчитаем первые шесть букв (от «-» до «т»); суммируя их вероятности (частоты), получим 0,498; на все остальные буквы (от «н» до «сф») придется приблизительно такая же вероятность 0,502. Первые шесть букв (от «-» до «т») будут иметь на первом месте двоичный знак 0. Остальные буквы (от «н» до «ф») будут иметь на первом месте единицу. Далее снова разделим первую группу на две приблизительно равновероятные подгруппы: от «-» до «о» и от «е» до «т»; для всех букв первой подгруппы на втором месте поставим нуль, а второй подгруппы"- единицу. Процесс будем продолжать до тех пор, пока в каждом подразделении не останется ровно одна буква, которая и будет закодирована определенным двоичным числом. Механизм построения кода показан на таблице 18.8.2, а сам код приведен в таблице 18.8.3.
Таблица 18.8.2.
|
Двоичные знаки |
|||||||||
Таблица 18.8.3
С помощью таблицы 18.8.3 можно закодировать и декодировать любое сообщение.
В виде примера запишем двоичным кодом фразу: «теория информации»
01110100001101000110110110000
0110100011111111100110100
1100001011111110101100110
Заметим, что здесь нет необходимости отделять друг от друга буквы специальным знаком, так как и без этого декодирование выполняется однозначно. В этом можно убедиться, декодируя с помощью таблицы 18.8.2 следующую фразу:
10011100110011001001111010000
1011100111001001101010000110101
010110000110110110
(«способ кодирования»).
Однако необходимо отметить, что любая ошибка при кодировании (случайное перепутывание знаков 0 и 1) при таком коде губительна, так как декодирование всего следующего за ошибкой текста становится невозможным. Поэтому данный принцип кодирования может быть рекомендован только в случае, когда ошибки при кодировании и передаче сообщения практически исключены.
Возникает естественный вопрос: а является ли составленный нами код при отсутствии ошибок действительно оптимальным? Для того чтобы ответить на этот вопрос, найдем среднюю информацию, приходящуюся на один элементарный символ (0 или 1), и сравним ее с максимально возможной информацией, которая равна одной двоичной единице. Для этого найдем сначала среднюю информацию, содержащуюся в одной букве передаваемого текста, т. е. энтропию на одну букву:
 ,
,
где - вероятность того, что буква примет определенное состояние («-», о, е, а,…, ф).
Из табл. 18.8.1 имеем
(дв. единиц на букву текста).
По таблице 18.8.2 определяем среднее число элементарных символов на букву
Деля энтропию на, получаем информацию на один элементарный символ
![]() (дв.
ед.).
(дв.
ед.).
Таким образом, информация на один символ весьма близка к своему верхнему пределу 1, а выбранный нами код весьма близок к оптимальному. Оставаясь в пределах задачи кодирования по буквам, мы ничего лучшего получить не сможем.
Заметим, что в случае кодирования просто двоичных номеров букв мы имели бы изображение каждой буквы пятью двоичными знаками и информация на один символ была бы
![]() (дв.
ед.),
(дв.
ед.),
т. е. заметно меньше, чем при оптимальном буквенном кодировании.
Однако надо заметить, что кодирование «по буквам» вообще не является экономичным. Дело в том, что между соседними буквами любого осмысленного текста всегда имеется зависимость. Например, после гласной буквы в русском языке не может стоять «ъ» или «ь»; после шипящих не могут стоять «я» или «ю»; после нескольких согласных подряд увеличивается вероятность гласной и т. д.
Мы знаем, что при объединении зависимых систем суммарная энтропия меньше суммы энтропий отдельных систем; следовательно, информация, передаваемая отрезком связного текста, всегда меньше, чем информация на один символ, умноженная на число символов. С учетом этого обстоятельства более экономный код можно построить, если кодировать не каждую букву в отдельности, а целые «блоки» из букв. Например, в русском тексте имеет смысл кодировать целиком некоторые часто встречающиеся комбинации букв, как «тся», «ает», «ние» и т. п. Кодируемые блоки располагаются в порядке убывания частот, как буквы в табл. 18.8.1, а двоичное кодирование осуществляется по тому же принципу.
В ряде случаев оказывается разумным кодировать даже не блоки из букв, а целые осмысленные куски текста. Например, для разгрузки телеграфа в предпраздничные дни целесообразно кодировать условными номерами целые стандартные тексты, вроде:
«поздравляю новым годом желаю здоровья успехов работе».
Не останавливаясь специально на методах кодирования блоками, ограничимся тем, что сформулируем относящуюся сюда теорему Шеннона.
Пусть имеется источник информации и приемник, связанные каналом связи (рис. 18.8.1).
![]()
Известна производительность источника информации, т. е. среднее количество двоичных единиц информации, поступающее от источника в единицу времени (численно оно равно средней энтропии сообщения, производимого источникам в единицу времени). Пусть, кроме того, известна пропускная способность канала, т. е. максимальное количество информации (например, двоичных знаков 0 или 1), которое способен передать канал в ту же единицу времени. Возникает вопрос: какова должна быть пропускная способность канала, чтобы он «справлялся» со своей задачей, т. е. чтобы информация от источника к приемнику поступала без задержки?
Ответ на этот вопрос дает первая теорема Шеннона. Сформулируем ее здесь без доказательства.
1-я теорема Шеннона
Если пропускная способность канала связи больше энтропии источника информации в единицу времени
то всегда можно закодировать достаточно длинное сообщение так, чтобы оно передавалось каналом связи без задержки. Если же, напротив,
то передача информации без задержек невозможна.
Поскольку является наиболее простой и соответствует требованиям:
- Чем меньше значений существует в системе, тем проще изготовить отдельные элементы, оперирующие этими значениями. В частности, две цифры двоичной системы счисления могут быть легко представлены многими физическими явлениями: есть ток - нет тока, индукция магнитного поля больше пороговой величины или нет и т. д.
- Чем меньше количество состояний у элемента, тем выше помехоустойчивость и тем быстрее он может работать. Например, чтобы закодировать три состояния через величину индукции магнитного поля, потребуется ввести два пороговых значения, что не будет способствовать помехоустойчивости и надёжности хранения информации.
- Двоичная арифметика является довольно простой. Простыми являются таблицы сложения и умножения - основных действий над числами.
- Возможно применение аппарата алгебры логики для выполнения побитовых операций над числами.
Ссылки
- Онлайн калькулятор для перевода чисел из одной системы счисления в другую
Wikimedia Foundation . 2010 .
Смотреть что такое "Бинарный код" в других словарях:
2 битный код Грея 00 01 11 10 3 битный код Грея 000 001 011 010 110 111 101 100 4 битный код Грея 0000 0001 0011 0010 0110 0111 0101 0100 1100 1101 1111 1110 1010 1011 1001 1000 Код Грея система счисления, в которой два соседних значения… … Википедия
Код сигнальной точки (англ. Signal Point Code (SPC)) сигнальной системы 7 (SS7, ОКС 7) это уникальный (в домашней сети) адрес узла, используемый на третьем уровне MTP (маршрутизация) в телекоммуникационных ОКС 7 сетях для идентификации … Википедия
В математике бесквадратным называется число, которое не делится ни на один квадрат, кроме 1. К примеру, 10 бесквадратное, а 18 нет, так как 18 делится на 9 = 32. Начало последовательности бесквадратных чисел таково: 1, 2, 3, 5, 6, 7,… … Википедия
Для улучшения этой статьи желательно?: Викифицировать статью. Переработать оформление в соответствии с правилами написания статей. Исправить статью согласно стилистическим правилам Википедии … Википедия
У этого термина существуют и другие значения, см. Python (значения). Python Класс языка: му … Википедия
В узком смысле слова в настоящее время под словосочетанием понимается «Покушение на систему безопасности», и склоняется скорее к смыслу следующего термина Крэкерская атака. Это произошло из за искажения смысла самого слова «хакер». Хакерская… … Википедия