Spin up time большое значение. S.M.A.R.T
Рано или поздно (лучше, конечно, если рано) любой пользователь задает себе вопрос о том, как долго еще протянет установленный у него на компьютере жесткий диск и не пора ли присмотреть ему замену. Удивительного в этом ничего нет, поскольку жесткие диски в силу своих конструктивных особенностей являются наименее надежными среди компьютерных комплектующих. При этом именно на HDD у большинства пользователей хранится львиная доля самой разнообразной информации: документов, снимков, разнообразного ПО и т.д., вследствие чего неожиданный выход диска из строя - всегда трагедия. Конечно, нередко информацию на внешне «мертвых» жестких дисках можно восстановить, но не исключено, что эта операция влетит вам «в копеечку», да и нервов будет стоить немалых. Поэтому гораздо эффективнее попытаться предупредить потерю данных.
Как? Очень просто… Во-первых, не забывать о регулярном резервном копировании данных, а во-вторых, контролировать состояние дисков с помощью специализированных утилит. Несколько программ такого плана в ракурсе решаемых задач мы и рассмотрим в данной статье.
Контроль SMART-параметров и температуры
Все современные HDD и даже твердотельные накопители (SSD) поддерживают технологию S.M.A.R.T. (от англ. Self-Monitoring, Analysis, and Reporting Technology - технология самоконтроля, анализа и отчетности), которая была разработана основными производителями жестких дисков для увеличения надежности их продукции. Данная технология базируется на непрерывном мониторинге и оценке состояния жесткого диска встроенной аппаратурой самодиагностики (специальными сенсорами), а ее основное предназначение - своевременное выявление возможного выхода накопителя из строя.
Мониторинг состояния HDD в реальном времени
Ряд информационнодиагностических решений для диагностики и тестирования «железа», а также специальные мониторинговые утилиты используют технологию S.M.A.R.T. для наблюдения за текущим состоянием различных жизненно важных параметров, описывающих надежность и производительность жестких дисков. Они считывают соответствующие параметры непосредственно с сенсоров и термодатчиков, которыми оснащены все современные жесткие диски, анализируют полученные данные и отображают их в виде краткого табличного отчета с перечнем атрибутов. При этом часть утилит (Hard Drive Inspector, HDDlife, Crystal Disk Info и т.п.) не ограничивается отображением таблицы атрибутов (значения которых для неподготовленных пользователей непонятны) и дополнительно выводит краткую информацию о состоянии диска в более доступном для понимания виде.
Диагностировать состояние жесткого диска с помощью такого рода утилит проще простого - достаточно ознакомиться с краткой базовой информацией об установленных HDD: с основными данными о дисках в Hard Drive Inspector, неким условным процентом здоровья жесткого диска в HDDlife, индикатором «Техсостояние» в Crystal Disk Info (рис. 1) и т.д. В любой из подобных программ предоставляется минимум необходимой информации о каждом из установленных на компьютере HDD: данные о модели винчестера, его объеме, рабочей температуре, отработанном времени, а также уровне надежности и производительности. Эта информация дает возможность сделать определенные выводы о работоспособности носителя.
Рис. 1. Краткая информация о «здоровье» рабочего HDD
Следует настроить запуск мониторинговой утилиты одновременно со стартом операционной системы, скорректировать интервал времени между проверками S.M.A.R.T.-атрибутов, а также включить отображение температуры и «уровня здоровья» жестких дисков в системном трее. После этого для контроля за состоянием дисков пользователю достаточно будет время от времени поглядывать на индикатор в системном трее, где будет отображаться краткая информация о состоянии имеющихся в системе накопителей: уровне их «здоровья» и температуре (рис. 2). Кстати, рабочая температура - это не менее важный показатель, чем условный показатель здоровья HDD, ведь жесткие диски могут внезапно выйти из строя вследствие банального перегрева. Поэтому если жесткий диск нагревается выше 50 °C, то разумнее будет обеспечить ему дополнительное охлаждение.

Рис. 2. Отображение состояния жесткого диска
в системном трее программой HDDlife
Стоит отметить, что в ряде таких утилит предусмотрена интеграция с проводником Windows, благодаря чему на иконках локальных дисков в случае их исправности отображается зеленый значок, а при возникновении проблем значок становится красным. Так что забыть о состоянии здоровья жестких дисков вам вряд ли удастся. При таком постоянном мониторинге вы не сможете пропустить момент, когда с диском начнут возникать какието проблемы, ведь в случае выявления утилитой критических изменений атрибутов S.M.A.R.T. и/или температуры она заботливо оповестит об этом пользователя (сообщением на экране, звуковым сообщением и т.д. - рис. 3). Благодаря этому можно будет успеть скопировать данные с внушающего опасение носителя заблаговременно.

Рис. 3. Пример сообщения о необходимости немедленной замены диска
Использовать на практике решения S.M.A.R.T.-мониторинга для наблюдения за состоянием жестких дисков совершенно необременительно, ведь все подобные утилиты работают в фоновом режиме и требуют минимум аппаратных ресурсов, поэтому их функционирование ни в коей мере не помешает основному рабочему процессу.
Контроль S.M.A.R.T.-атрибутов
Продвинутые пользователи, разумеется, вряд ли ограничатся для оценки состояния жестких дисков просмотром краткого вердикта одной из представленных выше утилит. Оно и понятно, ведь по расшифровке атрибутов S.M.A.R.T. можно выявить причину сбоев и при необходимости предусмотрительно предпринять какието дополнительные меры. Правда, для самостоятельного контроля S.M.A.R.T.-атрибутов потребуется хотя бы кратко ознакомиться с технологией S.M.A.R.T.
В состав поддерживающих эту технологию жестких дисков ивключены интеллектуальные процедуры самодиагностики, поэтому они способны «сообщать» о своем текущем состоянии. Данная диагностическая информация предоставляется как коллекция атрибутов, то есть конкретных характеристик жесткого диска, используемых для анализа его производительности и надежности.
Бо льшая часть важных атрибутов имеет один и тот же смысл для дисков всех производителей. Значения данных атрибутов при нормальной работе диска могут варьироваться в некоторых интервалах. Для любого параметра производителем определено некое минимально безопасное значение, которое не может быть превышено при нормальных условиях эксплуатации. Однозначно определить критически важные и критически неважные для диагностики параметры S.M.A.R.T. проблематично. Каждый из атрибутов имеет свою информационную ценность и свидетельствует о том или ином аспекте в работе носителя. Однако в первую очередь следует обращать внимание на следующие атрибуты:
- Raw Read Error Rate - частота ошибок чтения данных с диска, возникших по вине оборудования;
- Spin Up Time - среднее время раскрутки шпинделя диска;
- Reallocated Sector Count - число операций переназначения секторов;
- Seek Error Rate - частота появления ошибок позиционирования;
- Spin Retry Count - число повторных попыток раскрутки дисков до рабочей скорости в случае неудачности первой попытки;
- Current Pending Sector Count - количество нестабильных секторов (то есть секторов, ожидающих процедуру переназначения);
- Offline Scan Uncorrectable Count - общее количество нескорректированных ошибок во время операций чтения/записи секторов.
Обычно атрибуты S.M.A.R.T. отображаются в табличном виде с указанием имени атрибута (Attribute), его идентификатора (ID) и трех значений: текущего (Value), минимального порогового (Threshold) и самого низкого значения атрибута за всё время работы накопителя (Worst), а также абсолютного значения атрибута (Raw). Каждый атрибут имеет текущее значение, которое может быть любым числом от 1 до 100, 200 или 253 (общих стандартов для верхних границ значений атрибутов не предусмотрено). Значения Value и Worst у совершенно нового винчестера совпадают (рис. 4).

Рис. 4. Атрибуты S.M.A.R.T. у нового HDD
Приведенная на рис. 4 информация позволяет сделать вывод, что у теоретически исправного винчестера текущие (Value) и наихудшие (Worst) значения должны быть максимально близкими друг к другу, а значение Raw у большинства параметров (за исключением параметров: Power-On Time, HDA Temperature и некоторых других) должно приближаться к нулю. Текущее значение может со временем изменяться, что в большинстве случаев отражает ухудшение параметров жесткого диска, описываемых атрибутом. Это можно увидеть на рис. 5, где представлены фрагменты таблицы атрибутов S.M.A.R.T. для одного и того же диска - данные получены с интервалом в полгода. Как видим, в более свежей версии S.M.A.R.T. увеличилась частота ошибок при чтении данных с диска (Raw Read Error Rate), происхождение которых обусловлено аппаратной частью диска, и частота ошибок при позиционировании блока магнитных головок (Seek Error Rate), что, возможно, свидетельствует о перегреве винчестера и его неустойчивом положении в корзине. Если текущее значение какого-нибудь атрибута приближается или становится меньше порогового, то жесткий диск признается ненадежным, и его следует срочно менять. Например, падение значения атрибута Spin-Up Time (среднее время раскрутки шпинделя диска) ниже критического значения, как правило, сообщает о полном износе механики, вследствие чего диск больше не в состоянии поддерживать заданную производителем скорость вращения. Поэтому необходимо контролировать состояние HDD и периодически (например, раз в 2-3 месяца) проводить диагностику S.M.A.R.T. и сохранять полученную информацию в текстовом файле. В дальнейшем эти данные можно будет сравнить с текущими и сделать определенные выводы о развитии ситуации.

Рис. 5. Таблицы атрибутов S.M.A.R.T., полученные с полугодовым интервалом
(более свежая версия S.M.A.R.T. внизу)
При просмотре S.M.A.R.T.-атрибутов в первую очередь стоит обращать внимание на критически важные параметры, а также на параметры, выделенные отличными от базового цвета (чаще синего или зеленого) индикаторами. В зависимости от текущего состояния атрибута в выводимой утилитой S.M.A.R.T. таблице он обычно маркируется тем или иным цветом, что облегчает понимание ситуации. В частности, в программе Hard Drive Inspector цветовой индикатор может иметь зеленый, желтозеленый, желтый, оранжевый или красный цвет - зеленый и желтозеленый цвета говорят о том, что всё нормально (значение атрибута не менялось или несущественно менялось), а желтый, оранжевый и красный цвета сигнализируют об опасности (хуже всего красный цвет, который говорит о том, что значение атрибута достигло своего критического значения). Если какойто из критически важных параметров отмечен значком красного цвета, то нужно срочно заменить винчестер.
Просмотрим в программе Hard Drive Inspector таблицу S.M.A.R.T.-атрибутов того самого диска, краткая оценка которого мониторинговыми утилитами нами была приведена ранее. Из рис. 6 видно, что значения всех атрибутов в норме и все параметры промаркированы зеленым цветом. Аналогичную картину покажут и утилиты HDDlife и Crystal Disk Info. Правда, более профессиональные решения для анализа и диагностики HDD не столь лояльны и часто маркируют S.M.A.R.T.-атрибуты более придирчиво. К примеру, такие известные утилиты, как HD Tune Pro и HDD Scan, в нашем случае с подозрением отнеслись к атрибуту UltraDMA CRC Errors, который отображает число ошибок, возникающих при передаче информации по внешнему интерфейсу (рис. 7). Причина возникновения таких ошибок обычно связана с перекрученным и некачественным SATA-шлейфом, который, возможно, следует заменить.

Рис. 6. Таблица S.M.A.R.T.-атрибутов, полученная в программе Hard Drive Inspector

Рис. 7. Результаты оценки состояния S.M.A.R.T.-атрибутов
утилитами HD Tune Pro и HDD Scan
Для сравнения ознакомимся со S.M.A.R.T.-атрибутами очень древнего, но пока еще работающего HDD с периодически возникающими проблемами. Программе Crystal Disk Info доверия он не внушил - в индикаторе «Техсостояние» состояние диска было оценено как тревожное, а атрибут Reallocated Sector Count (Переназначенные сектора) оказался выделенным желтым цветом (рис. 8). Это весьма важный с точки зрения «здоровья» диска атрибут, обозначающий число секторов, переназначенных при обнаружении диском ошибки чтения/записи, при этой операции данные с поврежденного сектора переносятся в резервную область. Желтый цвет индикатора у параметра говорит о том, что оставшихся резервных секторов, которыми можно заменить сбойные, осталось мало, и вскоре переназначать вновь появляющиеся сбойные сектора окажется нечем. Проверим также, как оценивают состояние диска более серьезные решения, например широко используемая профессионалами утилита HDDScan, - но и здесь видим точно такой же результат (рис. 9).
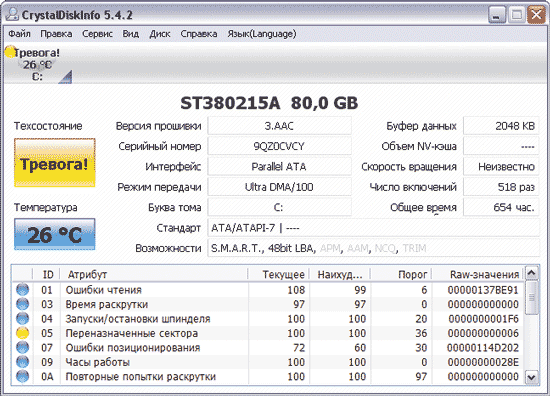
Рис. 8. Оценка проблемного жесткого диска в CrystalDiskInfo

Рис. 9. Результаты S.M.A.R.T.-диагностики HDD в HDDScan
Значит, с заменой такого жесткого диска тянуть явно не стоит, хотя он еще и может некоторое время послужить, правда операционную систему на данный жесткий диск устанавливать, конечно, нельзя. Стоит отметить, что при наличии большого числа переназначенных секторов скорость чтения/записи падает (вследствие лишних движений, которые приходится совершать магнитной головке), и диск начинает заметно тормозить.
Сканирование поверхности на bad-сектора
К сожалению, на практике одним контролем SMART-параметров и температуры не обойтись. При появлении мельчайших свидетельств о том, что с диском чтото не так (в случае периодического зависания программ, например при сохранении результатов, появлении сообщений об ошибках чтения и т.д.) необходимо просканировать поверхность диска на наличие нечитаемых секторов. Для проведения подобной проверки носителя можно воспользоваться, например, утилитами HD Tune Pro и HDDScan или диагностическими утилитами от производителей винчестеров, однако эти утилиты работают только со своими моделями жестких дисков, а потому рассматривать их мы не будем.
При использовании подобных решений существует опасность повреждения данных на сканируемом диске. С одной стороны, с информацией на диске, если накопитель действительно окажется неисправным, в ходе сканирования может случиться все что угодно. С другой стороны, нельзя исключать некорректных действий со стороны пользователя, по ошибке запускающего сканирование в режиме записи, в ходе которого происходит посекторное затирание данных с винчестера определенной сигнатурой, и на основании скорости этого процесса делается вывод о состоянии жесткого диска. Поэтому соблюдение определенных правил предосторожности совершенно необходимо: перед запуском утилиты нужно создать резервную копию информации и в ходе проверки действовать строго по инструкции разработчика соответствующего ПО. Для получения более точных результатов перед сканированием лучше закрыть все активные приложения и выгрузить возможные фоновые процессы. Кроме того, следует иметь в виду, что при необходимости тестирования системного HDD нужно загрузиться с флэшки и с нее запускать процесс сканирования либо совсем снять жесткий диск и подсоединить его к другому компьютеру, с которого и запускать тестирование диска.
В качестве примера с помощью HD Tune Pro проверим на плохие сектора поверхность HDD, который выше не внушил доверия утилите Crystal Disk Info. В этой программе для запуска процесса сканирования достаточно выбрать нужный диск, активировать вкладку Error Scan и щелкнуть на кнопке Start . После этого утилита приступит к последовательному сканированию диска, считывая сектор за сектором и отмечая на карте диска сектора разноцветными квадратиками. Цвет квадратиков в зависимости от ситуации может быть зеленым (нормальные сектора) или красным (bad-блоки) либо будет иметь некий промежуточный между этими цветами оттенок. Как видим из рис. 10, в нашем случае полноценных bad-блоков утилита не нашла, но тем не менее налицо солидное количество секторов с той или иной задержкой чтения (судя по их цвету). В дополнение к оному в средней части диска имеется небольшой блок секторов, цвет которого близок к красному - данные сектора пока утилитой не признаны сбойными, но они уже близки к этому и перейдут в категорию сбойных в самое ближайшее время.
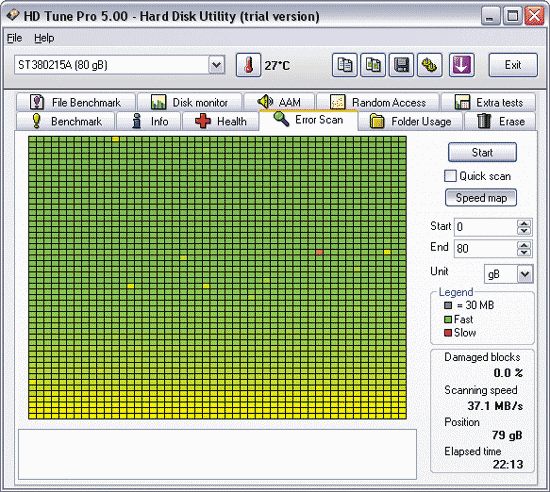
Рис. 10. Сканирование поверхности на bad-сектора в HD Tune Pro
Протестировать носитель на плохие сектора в программе HDDScan сложнее, да и опаснее, поскольку в случае неверно выбранного режима информация на диске будет безвозвратно утрачена. Первым делом для запуска сканирования создают новую задачу, щелкнув по кнопке New Task и выбрав в списке команду Suface Tests . Затем нужно удостовериться, что выбран режим Read - этот режим устанавливается по умолчанию и при его использовании тестирование поверхности жесткого диска производится по чтению (то есть без удаления данных). После этого нажимают на кнопку Add Test (рис. 11) и дважды щелкают на созданной задаче RD-Read . Теперь в открывшемся окне можно наблюдать процесс сканирования диска на графике (Graph) или на карте (Map) - рис. 12. По завершении процесса получим примерно такие же результаты, что выше были продемонстрированы утилитой HD Tune Pro, но с более четкой интерпретацией: сбойных секторов нет (они отмечаются синим цветом), но в наличии три сектора со временем отклика более 500 мс (помечены красным цветом), которые и представляют реальную опасность. Что касается шести оранжевых секторов (время отклика от 150 до 500 мс), то это можно считать в пределах нормы, поскольку такая задержка отклика зачастую вызывается временными помехами в виде, например, работающих фоновых программ.

Рис. 11. Запуск тестирования диска в программе HDDScan

Рис. 12. Результаты сканирования диска в режиме Read с помощью HDDScan
В дополнение следует отметить, что при наличии небольшого количества bad-блоков можно попытаться улучшить состояние жесткого диска, убрав плохие сектора путем сканирования поверхности диска в режиме линейной записи (Erase) с помощью программы HDDScan. После такой операции некоторое время диск еще может эксплуатироваться, но, конечно, не в качестве системного. Однако уповать на чудо не стоит, поскольку HDD уже начал сыпаться, и нет никаких гарантий, что в ближайшее время количество дефектов не возрастет и накопитель окончательно не выйдет из строя.
Программы для S.M.A.R.T.-мониторинга и тестирования HDD
HD Tune Pro 5.00 и HD Tune 2.55
Разработчик: EFD Software
Размер дистрибутива: HD Tune Pro - 1,5 Мбайт; HD Tune - 628 Кбайт
Работа под управлением: Windows XP/Server 2003/Vista/7
Способ распространения: HD Tune Pro - shareware (15-дневная демо-версия); HD Tune - freeware (http://www.hdtune.com/download.html)
Цена: HD Tune Pro - 34,95 долл.; HD Tune - бесплатно (только для некоммерческого применения)
HD Tune - удобная утилита для диагностики и тестирования HDD/SSD (см. таблицу), а также карт памяти, USB-дисков и ряда других устройств хранения данных. Программа отображает детальную информацию о накопителе (версия прошивки, серийный номер, объем диска, размер буфера и режим передачи данных) и позволяет установить состояние устройства с использованием данных S.M.A.R.T. и мониторинга температуры. Кроме того, с ее помощью можно провести тестирование поверхности диска на наличие ошибок и оценить производительность устройства, проведя серию тестов (тесты скорости последовательного и случайного чтения/записи данных, тест файловой производительности, тест кэша и ряд Extra-тестов). Также утилита может использоваться для настройки AAM и безопасного удаления данных. Программа представлена в двух редакциях: коммерческой HD Tune Pro и бесплатной облегченной HD Tune. В редакции HD Tune доступен только просмотр детальной информации о диске и таблицы атрибутов S.M.A.R.T., а также сканирование диска на ошибки и тестирование на скорость в режиме чтения (Low level benchmark - read).
За мониторинг S.M.A.R.T.-атрибутов в программе отвечает вкладка Health - считывание данных с сенсоров производится через установленный промежуток времени, результаты отображаются в таблице. Для любого атрибута можно просмотреть историю его изменений в численном виде и на графике. Данные мониторинга автоматически записываются в лог, но никаких уведомлений пользователя при критических изменениях параметров не предусмотрено.
Что касается сканирования поверхности диска на предмет наличия поврежденных секторов, то за эту операцию отвечает вкладка Error Scan . Сканирование может быть быстрым (Quick scan) и глубоким - при быстрой проверке проверяется не весь диск, а только какая-то его часть (зона сканирования определяется через поля Start и End). Поврежденные сектора отображаются на карте диска в виде красных блоков.
HDDScan 3.3
Разработчик: Artem Rubtsov
Размер дистрибутива: 3,64 Мбайт
Работа под управлением: Windows 2000(SP4)/XP(SP2/SP3)/Server 2003/Vista/7
Способ распространения: freeware (http://hddscan.com/download/HDDScan-3.3.zip)
Цена: бесплатно
HDDScan - утилита для низкоуровневой диагностики жестких дисков, твердотельных накопителей и Flash-дисков с интерфейсом USB. Основное предназначение данной программы - тестирование дисков на наличие bad-блоков и сбойных секторов. Также утилита может использоваться для просмотра содержимого S.M.A.R.T., мониторинга температуры и изменения некоторых настроек жесткого диска: управления шумом (AAM), управления питанием (APM), принудительного запуска/остановки шпинделя накопителя и др. Программа работает без установки и может запускаться с портативного носителя, например флэшки.
Отображение S.M.A.R.T.-атрибутов и мониторинг температуры в HDDScan производится по требованию. Отчет S.M.A.R.T. содержит информацию о производительности и «здоровье» накопителя в виде стандартной таблицы атрибутов, температура накопителя отображается в системном трее и в специальном информационном окне. Отчеты можно распечатывать или сохранять в MHT-файле. Возможно проведение S.M.A.R.T.-тестов.
Проверка поверхности диска производится в одном из четырех режимов: Verify (режим линейной верификации), Read (линейного чтения), Erase (линейной записи) и Butterfly Read (режим чтения Butterfly). Для проверки диска на наличие bad-блоков обычно используется тест в режиме чтения (Read), с помощью которого происходит тестирование поверхности без удаления данных (вывод о состоянии накопителя делается на основании скорости посекторного чтения данных). При тестировании в режиме линейной записи (Erase) информация на диске затирается, но зато данный тест может несколько подлечить диск, избавив его от сбойных секторов. В любом из режимов тестировать можно весь диск полностью либо определенный его фрагмент (зона сканирования определяется указанием начального и конечного логических секторов - Start LBA и End LBA соответственно). Результаты тестирования представляются в виде отчета (вкладка Report) и отображаются на графике (Graph) и карте диска (Map) с указанием в числе прочего количества сбойных секторов (Bads) и секторов, время отклика которых при тестировании заняло более 500 мс (помечены красным цветом).
Hard Drive Inspector 4.13
Разработчик: AltrixSoft
Размер дистрибутива: 2,64 Мбайт
Работа под управлением: Windows 2000/XP/2003 Server/Vista/7
Способ распространения: shareware (14-дневная демо-версия - http://www.altrixsoft.com/ru/download/)
Цена : Hard Drive Inspector Professional - 600 руб.; Hard Drive Inspector for Notebooks - 800 руб.
Hard Drive Inspector - удобное решение для S.M.A.R.T.-мониторинга внешних и внутренних HDD. В данный момент на рынке программа предлагается в двух редакциях: базовой Hard Drive Inspector Professional и портативной Hard Drive Inspector for Notebooks; последняя включает всю функциональность версии Professional, и в то же время учитывает специфику мониторинга жестких дисков ноутбуков. Теоретически существует еще версия SSD, но она распространяется только в OEM-поставках.
Программа обеспечивает автоматическую проверку S.M.A.R.T.-атрибутов через указанные промежутки времени и по завершении выдает свой вердикт относительно состояния накопителя с отображением значений неких условных индикаторов: «надежности», «производительности» и «отсутствия ошибок» вместе с числовым значением температуры и температурной диаграммой. Также приводятся технические данные о модели диска, его емкости, общем свободном месте и времени работы в часах (днях). В расширенном режиме можно посмотреть информацию о параметрах диска (размер буфера, название прошивки и т.д.) и таблицу атрибутов S.M.A.R.T. Предусмотрены разные варианты информирования пользователя в случае критических изменений на диске. Дополнительно утилита может быть использована для снижения уровня шума, производимого жесткими дисками, и снижения энергопотребления HDD.
HDDlife 4.0
Разработчик: BinarySense, Ltd
Размер дистрибутива: 8,45 Мбайт
Работа под управлением: Windows 2000/XP/2003/Vista/7/8
Способ распространения: shareware (15-дневная демо-версия - http://hddlife.ru/rus/downloads.html)
Цена : HDDLife - бесплатно; HDDLife Pro - 300 руб.; HDDlife for Notebooks - 500 руб.
HDDLife - простая утилита, предназначенная для контроля состояния жестких дисков и SSD (с версии 4.0). Программа представлена в трех редакциях: бесплатной HDDLife и двух коммерческих - базовой HDDLife Pro и портативной HDDlife for Notebooks.
Утилита осуществляет мониторинг S.M.A.R.T.-атрибутов и температуры через заданные промежутки времени и по результатам анализа выдает компактный отчет о состоянии диска с указанием технических данных о модели диска и его емкости, отработанном времени, температуре, а также отображает условный процент его здоровья и производительности, что позволяет сориентироваться в ситуации даже новичкам. Более опытные пользователи дополнительно могут посмотреть таблицу S.M.A.R.T.-атрибутов. В случае проблем с жестким диском предусмотрена возможность настройки уведомлений; можно настроить программу так, чтобы при нормальном состоянии диска результаты проверки не отображались. Возможно управление уровнем шума HDD и энергопотреблением.
CrystalDiskInfo 5.4.2
Разработчик: Hiyohiyo
Размер дистрибутива: 1,79 Мбайт
Работа под управлением: Windows XP/2003/Vista/2008/7/8/2012
Способ распространения: freeware (http://crystalmark.info/download/index-e.html)
Цена: бесплатно
CrystalDiskInfo - простая утилита для S.M.A.R.T.-мониторинга состояния жестких дисков (включая многие внешние HDD) и SSD. Несмотря на бесплатность программа обладает всем необходимым функционалом для организации контроля состояния дисков.
Мониторинг дисков производится автоматически через указанное число минут или по требованию. По окончании проверки в системном трее отображается температура контролируемых устройств; детальная информация об HDD с указанием значений S.M.A.R.T.-параметров, температуры и вердикта программы о состоянии устройств доступна в главном окне утилиты. Имеется функционал для настройки пороговых значений для некоторых параметров и автоматического уведомления пользователя в случае их превышения. Возможно управление уровнем шума (AAM) и питанием (APM).
К сожалению, немалая часть современных HDD нормально работает чуть больше года, потом начинаются разного рода проблемы, которые со временем могут привести к потере данных. Подобной перспективы вполне можно избежать, если внимательно следить за состоянием жесткого диска, например, с помощью рассмотренных в статье утилит. Однако забывать о регулярном резервировании ценных данных также не стоит, поскольку мониторинговые утилиты, как правило, удачно прогнозируют выход диска из строя по вине «механики» (согласно статистике компании Seagate, из-за механических компонентов выходят из строя около 60% HDD), но они не в состоянии предсказать гибель накопителя вследствие неполадок с электронными компонентами диска.
Новейшие накопители представлены интеллектуальными устройствами, способными анализировать свое состояние и своевременно информировать пользователя о неполадках. Для этого аппаратная часть включает оригинальную опцию S.M.A.R.T.

Назначение технологии SMART.
Львиная доля дисковых накопителей последних лет, функционирует с использованием технологии S.M.A.R.T. Сочетание расшифровывается как self-monitoring, analysis and reporting technology , что на русском звучит как механизм самоконтроля, анализа и отчетности. Ее первые разработки увидели свет в 1995 году и с тех пор технология постоянно совершенствуется.
С момента производства дисковый накопитель начинает считывать свое текущее состояние, определяя его с помощью специальных параметров или атрибутов. Они располагаются , доступ к которой имеет лишь встроенная программа. Просмотреть параметры позволяет отдельное ПО, чаще всего представленное утилитами от разработчиков конкретного жесткого диска. Через них в накопитель подаются вводные, после чего в журнале статистики появится информация о текущем состоянии диска.
В процессе эксплуатации накопителя, данные представленные в рамках параметров значения постоянно меняются. Параметры проходят путь с максимальных показателей, гарантирующих высокую производительность и эффективность до минимальных значений, связанных с высокой вероятностью выхода накопителя из строя.
Все представленные в рамках технологии S.M.A.R.T атрибуты имеет цифровой идентификатор. Как правило, он общий для накопителей различных версий, однако имеют место исключения. В данном отношении выделяется цифра 7, демонстрирующая ошибки в размещении головок на дисковую поверхность. Для цифровой идентификатор неактуален. В отличие от 7-ки, цифра 9, которая показывает общий период непосредственной работы накопителя за срок использования, ее поддерживают все типы дисков HDD и SSD.
Структура параметров, представлена несколькими полями, демонстрирующих состояние диска и его разделов в конкретный период. Предназначенные для считывания информации утилиты выводят на экран следующие параметры:
- ID – идентификационный номер
- name – название атрибута
- VAL – его текущее состояние
- Wrst – наихудший показатель за период эксплуатации
- Thresh – минимальный порог работоспособности
Показатели S.M.A.R.T
Существует несколько самых распространенных параметров. Они, за редким исключением, объединяют накопители большинства производителей, итак:
- Raw Read Error Rate – показатель числа ошибок считывания
- Throughput Performance – рабочая эффективность. Ее снижение указывает на необходимость замены
- Spin Up Time – период развертывания накопителя в рабочее состояние. Рост параметра демонстрирует изношенность или недостаток питания
- Start/Stop Count – показатель количества моментов развертывания диска, которое изначально ограничено его механической структурой
- Reallocated Sectors Count – атрибут отражает число запасных участков. Туда при неполадках перенаправляется информация. В идеале количество подобных действий должно составлять 0
- Read Channel Margin – канальный резерв. В наше время накопители обходятся без него
- Seek Error Rate – Отражение механического состояния накопителя, в числе прочего демонстрирует излишнюю вибрацию и перегрев
- Seek Time Performance – уровень оперативных возможностей, актуален лишь для дисков HDD
- Power-on Time – прогноз продолжительности функционирования накопителя исходя из периода эксплуатации. Максимальные показатели составляют 100 и с течением времени снижаются до 0
- Spin-Up Retry Count – количество дублирующих операций запуска. Их увеличение говорит об ошибках в механической структуре
Эти и другие атрибуты, идущие красным фоном, говорят о его критическом состоянии накопителя, что предполагает скорую поломку. Конкретного стандарта, объединяющего показатели параметров от различных производителей, не существует. В каждом случае нормальные значения индивидуальны, отражаясь в виде фона или статуса, где
- Good – хороший показатель
- Bad – плохой показатель.


Наряду с уже упомянутыми атрибутами следует уделять внимание таким параметрам как:
- Recalibration Retries – число дублей при рекаблировке. Их повышение свидетельствует о неполадках механики
- End-to-End error – Недостатки обменных операций
- Reported UNC Errors – неполадки, чье устранение ведется с помощью аппаратных средств
- G-sense error rate – количество механических воздействий на диск. Фиксирует неаккуратную установку, столкновения
- Reallocation Event Count – общий показатель операций перенаправления информации. Фиксирует удачные и неудачные операции
- Current Pending Sector Count – количество потенциальных участков накопителя, подлежащих замене
- Uncorrectable Sector Count – количество неисправных секторов, неподлежащих восстановлению
- UltraDMA CRC Error Count – неполадки перенаправления данных между накопителем и ПК
Проверка S.M.A.R.T
Параметры S.M.A.R.T проверяются при помощи специальных утилит от производителей жестких дисков. Существуют и универсальные программы для тестирования и проверки дисков. Среди них выделяются udisks, smartctl, hddscan, CrystalDiskInfo, Victoria, используя которые пользователь сможет оценить состояние жесткого диска. В некоторых случаях, а именно при работе с контроллерами RAID, получить дисковые атрибуты практически невозможно.


Минимальный уровень диагностики поддерживается на уровне BIOS. Если включен режим диагностики S.M.A.R.T., то при наличии критических значений атрибутов BIOS не позволит загрузиться операционной системе.
Итак, тестируя состояние жесткого диска, прежде всего внимание, уделяется указанным параметрам S.M.A.R.T . Основное назначение технологии – прогнозирование выхода их строя жесткого диска. При опасном отклонении показателей от нормы, имеет смысл переносить важную информацию на другие носители.
И, самое главное, даже если в S.MA.R.T. никаких ошибок нет и все хорошо, это не является гарантией, что диск не сломается, так что .
Все современные накопители на жестких магнитных дисках поддерживают технологию самотестирования, анализа состояния, и накопления статистических данных об ухудшении собственных характеристик S.M.A.R.T. (Self-Monitoring Analysis and Reporting Technology). Основы S.M.A.R.T. были разработаны в 1995 г. совместными усилиями ведущих производителями жестких дисков. В процессе совершенствования оборудования накопителей, возможности технологии также дорабатывались, и после стандарта SMART появился SMART II, затем - SMART III, который, очевидно, тоже не станет последним.
Жесткий диск в процессе своего функционирования постоянно отслеживает определенные параметры своего состояния и отражает их в специальных характеристиках - атрибутах (Attribute), сохраняющихся, как правило, в специально выделенной части дисковой поверхности, доступной только внутренней микропрограмме накопителя - служебной зоне . Данные атрибутов могут быть считаны специальным программным обеспечением.
Атрибуты идентифицируются своим цифровым номером, большинство из которых одинаково интерпретируется накопителями разных моделей. Некоторые атрибуты могут быть определены конкретным производителем оборудования, и поддерживаться только отдельными моделями накопителей.
Атрибуты состоят из нескольких полей, каждое из которых имеет определенный смысл. Обычно, программы считывания S.M.A.R.T. выдают расшифровку атрибутов в виде:
- Attribute - имя атрибута
- ID - идентификатор атрибута
- Value - текущее значение атрибута
- Threshold - минимальное пороговое значения атрибута
- Worst - самое низкое значение атрибута за все время работы накопителя
- Raw - абсолютное значение атрибута
- Type (необязательно) - тип атрибута - характеризует производительность (PR - Performance-related), характеризует сбои (ER - Error rate), счетчик событий (EC - Events count), определено производителем или не используется (SP - Self-preserve);
Для анализа состояния накопителя, пожалуй, самым важным значением атрибута является Value - условное число (обычно от 0 до 100 или до 253), заданное производителем. Значение Value изначально установлено на максимум при производстве накопителя и уменьшается в случае ухудшения его параметров.
Для каждого атрибута существует пороговое значение, до достижения которого, производитель гарантирует его работоспособность - поле Threshold . Если значение Value приближается или становится меньше значения Threshold, - накопитель пора менять. Перечень атрибутов и их значения жестко не стандартизированы и определяются изготовителем накопителя, но наиболее важные из них интерпретируются одинаково.
Например, атрибут с идентификатором 5 (Reallocated sector count ) будет характеризовать число забракованных и переназначенных из резервной области секторов диска, и для устройств производства компании Seagate, и для Western Digital, Samsung, Maxtor.
Жесткий диск не имеет возможности, по собственной инициативе, передать данные SMART потребителю. Их считывание выполняется специальным программным обеспечением.
В настройках большинства современных BIOS материнских плат имеется пункт позволяющий запретить или разрешить считывание и анализ атрибутов SMART в процессе выполнения тестов оборудования перед выполнением начальной загрузки системы. Включение опции позволяет подпрограмме тестирования оборудования BIOS считать значения критических атрибутов и, при превышении порога, предупредить об этом пользователя. Как правило, без особой детализации:
Primary Master Hard Disk: S.M.A.R.T status BAD!, Backup and Replace.
Выполнение подпрограммы BIOS приостанавливается, чтобы привлечь внимание:
Таким образом, без установки или запуска дополнительного программного обеспечения, имеется возможность вовремя определить критическое состояние накопителя (при включении данной опции) средствами Базовой Системы Ввода-Вывода (BIOS).
Анализ данных S.M.A.R.T. жесткого диска
Для получения данных SMART в среде операционной системы могут использоваться специальные программы, в частности, практически все утилиты для тестирования оборудования жестких дисков.
Одной из самых популярных программ для тестирования жестких дисков является Victoria Сергея Казанского. На сайте автора найдете последнюю версию программы, а также массу полезной информации, в том числе и подробное описание работы с Victoria.
Программа Victoria имеет две разновидности - для работы в среде DOS и, для работы в среде Windows. DOS-версия может напрямую работать с контроллером жесткого диска и обладает значительно большими возможностями по сравнению с версией для Windows. Назначение, основные возможности и порядок использования программы раньше можно было найти на сайте автора , но с некоторых пор сайт заброшен и информации там нет.
Программа проста в использовании и позволяет оценить техническое состояние накопителя, выполнить его тестирование и некоторые настройки - уровня шума, производительности, физического объема. Режимы тестирования поверхности накопителя позволяют принудительно избавиться от сбойных секторов с помощью режима Remap нескольких видов. Вызов меню тестирования выполняется по нажатию клавиши F4 (SCAN ). Пользователь имеет возможность задать область тестирования:
- Start LBA:0 - начало области (по умолчанию - 0)
- End LBA:14680064 - конец области (по умолчанию - номер последнего блока диска)
Режим тестирования:
- Линейное чтение - последовательное чтение от начального блока до конечного;
- Случайное чтение - номер считываемого блока формируется случайным образом;
- BUTTERFLY чтение - выполняется чтение блоков, начиная от граничных номеров (начала и конца), к центру области тестирования. Изменение режима выполняется по нажатию клавиши "пробел".
Режим обработки ошибок . Этот пункт позволяет выполнить скрытие дефектных блоков, с использованием переназначения (ремап) из резервной области. Выбор режима выполняется клавишей "пробел". Выбранный метод работы с дефектами отображается в правом верхнем углу экрана, под часами, а также в нижней строке в момент запуска теста. Изменить режим можно в и в процессе выполнения сканирования.
- Ignore Bad Blocks - программа не будет выполнять никаких действий при обнаружении ошибки.
- BB = RESTORE DATA - программа попытается восстановить данные из поврежденных секторов.
- BB = Classic REMAP - выполняется запись в поврежденный сектор для вызова процедуры переназначения.
- BB = Advanced REMAP - улучшенный алгоритм скрытия сбойных блоков. Используется, когда не помогает классический ремап. Программа выполняет специальную последовательность операций с целью формирования признака кандидата на ремап (атрибут 197) у сбойного блока. Затем выполняется 10-кратная запись, обрабатываемая микропрограммой накопителя как обычная обработка кандидата на ремап - если есть ошибка, выполняется переназначение, если нет ошибки - блок считается нормальным и удаляется из кандидатов на ремап. Данный режим позволяет выполнить скрытие сбойных блоков без потери пользовательских данных. Конечно, только в случаях, когда накопитель технически исправен и есть свободное место в резервной области для переназначения.
- BB = Fujitsu Remap - выполнение специфических алгоритмов, основанных на недокументированных возможностях некоторых моделей накопителей Fujitsu
- BB = Erase 256 sect - при обнаружении сбойного сектора выполняется перезаписывание блока из 256 секторов. Пользовательские данные не сохраняются.
В процессе работы с программой можно вызвать контекстную справку клавишей F1
Версия Victoria For Windows обладает более скромными возможностями по настройке накопителя и выбору режимов тестирования, и на данный момент не имеет поддержки русского языка, однако ей проще пользоваться и имеющихся возможностей вполне достаточно для считывания таблицы SMART и оценки технического состояния накопителя.
Программа не требует установки, просто скачайте последнюю версию по ссылке Victoria v4.47 с нашего сайта.
Программа должна выполняться под учетной записью с павами администратора. В среде Windows 7 / 8 необходимо использовать контекстное меню “Запуск от имени администратора”.
Для анализа состояния SMART-атрибутов выбираем режим работы через программный интерфейс Windows - включаем кнопку API в правой верхней части основного окна. Затем выбираем накопитель для проверки - нажимаем на кнопку Standard в основном меню программы и подсвечиваем мышкой нужный диск в окне со списком.
В информационном окне будет отображен паспорт накопителя - модель, версию аппаратной прошивки, серийный номер, размер и т.п. Для получения данных SMART выбираем пункт меню SMART и жмем кнопку "Get SMART". Результат будет отображен в информационном окне программы.
Краткое описание атрибутов (в скобках дано шестнадцатеричное значение номера):
- 001 (1) Raw Read Error Rate - абсолютное значение ошибок считывания. Существует некоторые отличия в формировании значения данного атрибута разными производителями. Из практики могу сказать, что накопители Seagate могут иметь гигантское значение RAW этого атрибута, реально будучи в хорошем состоянии, а накопители Western Digital могут иметь его нулевым, имея критические показатели по другим характеристикам. Некоторые модели вообще могут не поддерживать данный атрибут.
- 003 (3) Spin Up Time - Среднее время раскрутки шпинделя диска от 0 RPM до рабочей скорости.
- 004 (4) Start/Stop Count - Количество циклов запуск/останов шпинделя.
- 005 (5) Reallocated Sector Count - Количество переназначенных секторов. Современные накопители имеют довольно большую (тысячи секторов) резервную область поверхности накопителя для использования ее в случае ухудшения характеристик секторов из основной зоны. Если накопитель обнаруживает проблемы с записью/считыванием какого - либо сектора, то он автоматически перемещает его данные в резервную область, а данный сектор помечается как "переназначенный". Часто этот процесс называют "remapping", или "automatic defect reassignment", он выполняется микропрограммой накопителя и для пользователя (операционной системы) невидим. Поле raw value содержит общее количество переназначенных секторов. Даже некритическое, но большое значение этого поля, может привести к снижению скорости обмена данными, поскольку накопитель выполняет дополнительную операцию установки головок на дорожки резервной области, обычно расположенной в конце диска.
- 007 (7) Seek Error Rate - Частота появления ошибок позиционирования блока магнитных головок (БМГ) . Накопитель контролирует правильность установки головок на требуемую дорожку поверхности. В случае, когда установка выполнилась неверно, фиксируется ошибка и операция повторяется. Для данного накопителя причиной большого числа ошибок явился перегрев.
- 008 (8) Seek Time Performance - средняя скорость позиционирования магнитных головок. Если значение атрибута уменьшается (замедление позиционирования), то велика вероятность проблем с механической частью привода головок.
- 009 (9) Power-On Hours - Количество часов во включенном состоянии. Достижение предельного значения этого атрибута означает выработку накопителем заданной производителем наработки на отказ (MTBF - Mean Time Between Failures).
- 010 (0A) Spin Retry Count - Количество повторных попыток старта шпинделя. После включения питания, накопитель раскручивает диски и контролирует достижение рабочей скорости вращения для данного устройства (например 5400 , 7200, 10000 об/мин.) за определенное время. В случае неудачи - увеличивается счетчик повторов и повторяется попытка старта.
- 011 (0B) Recalibration Retries - количество попыток рекалибровки, в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность проблем с механической частью накопителя. Кроме того, увеличение абсолютного значения данного атрибута может быть вызвано тем, что процедура рекалибровки используется внутренней микропрограммой накопителя для коррекции других типов ошибок.
- 012 (0C) Device Power Cycle Count - Количество циклов включения/выключения диска.
- 184 (B8) End-to-End error - Данный атрибут - часть технологии HP SMART IV - означает, что после передачи данных через буферную память чётность данных между контроллером компьютера и жестким диском не совпадает.
- 187 (BB) Reported Uncorrectable Error - Характеризует количество ошибок, которые не были исправлены микропрограммой накопителя.
- 188 (BC) Command Timeout Количество прерванных операций в связи с HDD тайм-аут. Обычно это значение атрибута должно быть равно нулю, и, если значение гораздо выше нуля, то, скорее всего, там будут какие-то серьезные проблемы с питанием или окислением контактов интерфейсного кабеля.
- 189 (BD) High Fly Writes - Если высота полета головки над магнитной поверхностью, даже на короткое время превысит оптимальную, то записанные ею данные, в дальнейшем, могут не прочитаться. Современные накопители используют специально разработанную технологию контроля высоты полета головок, позволяющую не выполнять запись данных при неоптимальной высоте. В счетчик данного атрибута добавляется единица, а запись выполняется после установки нормальной высоты полета. Повышенное значение данного атрибута может быть вызвано внешними ударами или вибрациями, ненормальной температурой, ухудшением характеристик магнитной поверхности или головки.
- 190 (BE) Airflow Temperature - температура окружающей среды блока магнитных головок. Для большинства моделей данный атрибут отсутствует и используется атрибут 194.
- 191 (BF) G-sense error rate - количество ошибок, возникающих в результате ударных нагрузок. Атрибут хранит показания встроенного акселерометра, который фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера. Обычно довольно точно характеризует условия эксплуатации ноутбуков - большое значение атрибута говорит о резких толчках и падениях при работе устройства.
- 192 (C0) Power-off retract count - количество циклов выключений или аварийных отказов (включений/выключений питания накопителя).
- 193 (C1) Load/Unload Cycle - количество циклов перемещения блока магнитных головок в зону парковки.
- 194 (C2) HDA Temperature - температура самого накопителя (HDA - Hard Disk Assembly). В данном атрибуте хранятся показания встроенного температурного датчика, которым обычно служит одна из магнитных головок (как правило - нижняя). Данные, записанные в полях атрибута отображают текущую, минимальную и максимальную температуру. Поле Worst показывает наихудшую, достигнутую за время работы накопителя, температуру (можно установить факт перегрева и его степень), raw value - текущую температуру. Некоторые модели накопителей могут поддерживать атрибут 205 (CD) Thermal asperity rate (TAR) фиксирующий количество опасных перепадов температуры.
- 195 (C3) Hardware ECC recovered - характеризует количество ошибок считывания, исправленных оборудованием накопителя с применением кода коррекции ошибок. Подобные ошибки не требуют повторного считывания сектора, и не приводят к потере скорости обмена данными, но большое их количество говорит об ухудшении параметров тракта считывания.
- 196 (C4) Reallocation Event Count - Число событий переназначения сбойных секторов. В поле raw value данного атрибута хранится общее число попыток переноса данных из нестабильных секторов в резервную область. Учитываются как успешные, так и неуспешные попытки.
- 197 (C5) Current Pending Sector Count - Текущее количество нестабильных секторов. Поле raw value этого атрибута показывает общее количество секторов, которые накопитель в данный момент считает кандидатами на переназначение в резервную область (remap). Если в дальнейшем какой-то из этих секторов будет прочитан успешно, то он исключается из списка кандидатов. Если же чтение сектора будет сопровождаться ошибками, то накопитель попытается восстановить данные и перенести их в резервную область, а сам сектор пометить как переназначенный (remapped).
- 198 (C6) Uncorrectable Sector Count - Счетчик некорректируемых ошибок. Это ошибки, которые не были исправлены внутренними средствами коррекции оборудования накопителя. Может быть вызвано неисправностью отдельных элементов или отсутствием свободных секторов в резервной области диска, когда возникла необходимость переназначения.
- 199 (C7) UltraDMA CRC Error Count - Счетчик ошибок, возникших при передаче данных в режиме UltraDMA . Аппаратные средства контроля передачи данных из накопителя в оперативную память обнаружили ошибку контрольной суммы. Нередко этот тип ошибки связан не столько с оборудованием накопителя, сколько с неисправным интерфейсным кабелем, нестабильным питанием, разгоном частоты шины PCI, перегревом микросхем чипсета материнской платы и т.п.
- 200 (C8) Write Error Rate (Multi-Zone Error Rate) - Характеризует наличие ошибок при записи данных. Может быть вызвано ухудшением состояния поверхности, головок или характеристик тракта записи данных. Чем ниже значение Value, тем опаснее использовать такой накопитель.
- 220 (DC) Disk Shift - смещение блока дисков относительно вертикальной оси шпинделя. В основном возникает из-за сильного удара или падения накопителя и как правило, является сигналом для его замены.
- 228 (E4) Power-Off Retract Cycle - Количество автоматических парковок магнитных головок при выключения питания.
Современные накопители поддерживают не только формирование атрибутов S.M.A.R.T, но и ведут дополнительные журналы статистики, а также поддерживают протокол SCT (SMART Command Transport), обеспечивающий считывание данных журналов. Журнал статистики устройства - это доступный только для чтения журнал SMART, передаваемый накопителем при получении команд READ LOG EXT, READ LOG DMA EXT или SMART READ LOG. В журналах отображается информация о выполнении встроенных тестов S.M.A.R.T (self-test), статистика ошибок, номера сбойных блоков LBA и т.п.
Сегодня, хотелось бы чуточку подробнее поговорить о вскользь упомянутой в предыдущей статье о критериях выбора винчестера технологии SMART, а также выяснить вопрос о появлении плохих секторов при проверке поверхности специальными программами и исчерпании резервной поверхности для их переназначения - вопросу, поднятому на из прошлой статьи.
Для начала как всегда краткий исторический экскурс. Надежность жесткого диска (и любого устройства хранения в самом общем случае) всегда придается огромное значение. И дело отнюдь не в его стоимости, а в ценности той информации, которую он уносит с собой в мир иной, уходя из жизни сам, и в потерях прибыли, связанных с простоями при выходе из строя винчестеров, если речь идет о бизнес-пользователях, даже в том случае, если информация осталась. И вполне естественно, что о таких неприятных моментах хочется знать заранее. Даже обычные рассуждения на бытовом уровне подсказывают, что наблюдение за состоянием прибора в работе, может подсказать такие моменты. Осталось только каким-то образом реализовать это наблюдение в винчестере.
Впервые над этой задачей задумались инженеры голубого гиганта (IBM то бишь). И в 1995 году они предложили технологию, отслеживающую несколько критически важных параметров накопителя, и делающую попытки на основании собранных данных предсказать выход его из строя - Predictive Failure Analysis (PFA). Идею подхватила Compaq, которая чуть позже создала свою технологию - IntelliSafe. В разработке Compaq также поучаствовали Seagate, Quantum и Conner. Созданная ими технология также отслеживала ряд рабочих характеристик диска, сравнивала их с допустимым значением и рапортовала хост-системе в случае наличия опасности. Это был огромный шаг вперед если и не в повышении надежности винчестеров, то хотя бы в уменьшении риска потери информации при их использовании. Первые попытки оказались удачными, и показали необходимость дальнейшего развития технологии. Уже в объединении всех крупных производителей жестких дисков появилась технология S.M.A.R.T (Self Monitoring Analysing and Reporting Technology), базирующаяся на технологиях IntelliSafe и PFA (кстати говоря, PFA существует и поныне, как набор технологий для наблюдения и анализа за различными подсистемами серверов IBM, в том числе и дисковой подсистемой, причем наблюдение за последней базируется именно на технологии SMART).
Итак, SMART - это технология внутренней оценки состояния диска, и механизм предсказания возможного выхода из строя жесткого диска. Важно отметить то, что технология в принципе не решает возникающих проблем (основные из них показаны на рисунке чуть ниже), она способна лишь предупредить об уже возникшей проблеме либо об ожидающейся в ближайшем времени.
При этом нужно также сказать, что технология не в состоянии предсказать абсолютно все возможные проблемы и это логично: выход электроники в результате скачка напряжения, порча головок и поверхности в результате удара и т.п. никакая технология предсказать не в силах. Предсказуемы лишь те проблемы, которые связаны с постепенным ухудшением каких-либо характеристик, равномерной деградацией каких либо компонент.
Этапы развития технологии
В своем развитии технология SMART прошла три этапа. В первом поколении было реализовано наблюдение небольшого числа параметров. Никаких самостоятельных действий накопителя не предусматривалось. Запуск осуществлялся только командами по интерфейсу. Спецификации описывающей стандарт полностью нет, и, следовательно, не было и нет и четкого предначертания, о том, какие именно параметры надлежит контролировать. Более того, их определение и определение допустимого уровня их снижения целиком и полностью предоставлялся производителям винчестеров (что естественно в силу того, что производителю виднее что именно надлежит контролировать данном его винчестере, ибо все винчестеры слишком различны). И программное обеспечение, по этой причине, написанное, как правило, сторонними фирмами, не было универсальным, и могло ошибочно рапортовать о предстоящем сбое (путаница возникала из-за того, что под одним и тем же идентификатором различные производители хранили значения различных параметров). Имело место большое число жалоб на то, что число случаев обнаружения пред сбойного состояния чрезвычайно мало (особенности человеческой природы: получать хочется все и сразу, жаловаться на внезапные отказы дисков до внедрения SAMRT в голову как-то никому не приходило). Ситуация усугубилась еще и тем, что в большинстве случаев не были выполнены минимально необходимые требования для функционирования SMART (об этом поговорим позже). Статистика говорит о том, что число предсказываемых сбоев было менее 20%. Технология на этом этапе была далека от совершенства, но являлась революционным шагом вперед.
О втором этапе развития SMART - SMART II известно также не много. В основном наблюдались те же проблемы, что и с первой. Нововведениями являлись возможность фоновой проверки поверхности, выполняемая диском в автоматическом режиме при простоях и ведение журналов ошибок, расширился список контролируемых параметров (снова же в зависимости от модели и производителя). Статистика говорит о том, что число предсказываемых сбоев достигло 50%.
Современный этап представлен технологией SMART III. На ней остановимся подробней, попытаемся разобраться в общих чертах как она работает, что и зачем в ней нужно.
Нам уже известно, что SMART производит наблюдение за основными характеристиками накопителя. Эти параметры называются атрибутами. Необходимые к мониторингу параметры определяются производителем. Каждый атрибут имеет какую-то величину - Value. Обычно изменяется в диапазоне от 0 до 100 (хотя может быть в диапазоне до 200 или до 255), ее величина - это надежность конкретного атрибута относительно некоторого его эталонного значения (определяется производителем). Высокое значение говорит об отсутствии изменений данного параметра или, в зависимости от значения, его медленном ухудшении. Низкое значение говорит о быстрой деградации или о возможном скором сбое, т.е. чем выше значение Value атрибута, тем лучше. Некоторыми программами мониторинга выводится значение Raw или Raw Value - это значение атрибута во внутреннем формате (который так же различен у дисков разных моделей и разных производителей), в том, в котором он хранится в накопителе. Для простого пользователя он малоинформативен, больший интерес представляет посчитанное из него значение Value. Для каждого атрибута производителем определяется минимальное возможное значение, при котором гарантируется безотказная работа накопителя - Threshold. При значении атрибута ниже величины Threshold очень вероятен сбой в работе или полный отказ. Осталось только добавить, что атрибуты бывают критически важными и некритически. Выход критически важного параметра за пределы Threshold фактический означает выход из строя, выход за переделы допустимых значений некритически важного параметра свидетельствует о наличии проблемы, но диск может сохранять свою работоспособность (хотя, возможно, с некоторым ухудшением некоторых характеристик: производительности например).
К наиболее часто наблюдаемым критически важным характеристикам относятся: Raw Read Error Rate - частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска.
Spin Up Time - время раскрутки пакета дисков из состояния покоя до рабочей скорости. При расчете нормализованного значения (Value) практическое время сравнивается с некоторой эталонной величиной, установленной на заводе. Не ухудшающееся немаксимальное значение при Spin Up Retry Count Value = max (Raw равном 0) не говорит ни о чем плохом. Отличие времени от эталонного может быть вызвано рядом причин, например блок питания подкачал.
Spin Up Retry Count - число повторных попыток раскрутки дисков до рабочей скорости, в случае если первая попытка была неудачной. Ненулевое значение Raw (соответственно немаксимальное Value) свидетельствует о проблемах в механической части накопителя.
Seek Error Rate - частота ошибок при позиционировании блока головок. Высокое значение Raw свидетельствует о наличии проблем, которыми могут являться повреждение сервометок, чрезмерное термическое расширение дисков, механические проблемы в блоке позиционирования и др. Постоянное высокое значение Value говорит о том, что все хорошо.
Reallocated Sector Count - число операций переназначения секторов. SMART в современных способен произвести анализ сектора на стабильность работы "на лету" и в случае признания его сбойным произвести его переназначение. Ниже мы поговорим об этом подробнее.
Из некритических, так сказать информационных атрибутов, обычно производят наблюдение за следующими:
Все происходящие ошибки и изменения параметров фиксируются в журналах SMART. Эта возможность появилась уже в SMART II. Все параметры журналов - назначение, размер, их число определяются изготовителем винчестера. Нас с вами в настоящий момент интересует только факт их наличия. Без подробностей. Информация хранящаяся в журналах используется для анализа состояния и составления прогнозов.
Если не вдаваться в подробности, то работа SMART проста - при работе накопителя просто отслеживаются все возникающие ошибки и подозрительные явления, которые находят отражение в соответствующих атрибутах. Кроме того начиная так же со SMART II у многих накопителей появились функции самодиагностики. Запуск тестов SMART возможен в двух режимах, off-line - тест выполняется фактически в фоновом режиме, так как накопитель в любое время готов принять и выполнить команду, и монопольном при котором при поступлении команды, выполнение теста завершается.
Документировано существует три типа тестов самодиагностики: фоновый сбор данных (Off-line collection), сокращенный тест (Short Self-test), расширенный тест (Extended Self-test). Два последних способны выполняться как в фоновом, так и в монопольном режимах. Набор тестов в них входящих не стандартизирован.
Продолжительность их выполнения может быть от секунд до минут и часов. Если вы вдруг не обращаетесь к диску, а он при этом издатет звуки как и при рабочей нагрузке - он просто похоже занимается самоанализом. Все данные собранне в результате таких тестов будут также сохранены в журналах и аттрибутах.
Ох уж эти плохие сектора...
Теперь вернемся к вопросу бэд-секторов, с которых все началось. В SMART III появилась функция, позволяющая прозрачно для пользователя переназначать BAD сектора. Работает механизм достаточно просто, при неустойчивом чтении сектора, или же ошибки его чтения, SMART заносит его в список нестабильных и увеличит их счетчик (Current Pending Sector Count). Если при повторном обращении сектор будет прочитан без проблем, он будет выброшен из этого списка. Если же нет, то при предоставившейся возможности - при отсутствии обращений к диску, диск начнет самостоятельную проверку поверхности, в первую очередь подозрительных секторов. Если сектор будет признан сбойным, то он будет переназначен на сектор из резервной поверхности (соответственно RSC увеличиться). Такое фоновое переназначение приводит к тому, что на современных винчестерах сбойные секторы практически никогда не видны при проверке поверхности сервисными программами. В тоже время, при большом числе плохих секторов их переназначение не может происходить до бесконечности. Первый ограничитель очевиден - это объем резервной поверхности. Именно этот случай я имел ввиду. Второй не столь очевиден - дело в том, что у современных винчестеров есть два дефект-листа P-list (Primary, заводской) и G-list (Growth, формируется непосредственно во время эксплуатации). И при большом числе переназначений может оказаться так, что в G-list не оказывается места для записи о новом переназначении. Эта ситуация может быть выявлена по высокому показателю переназначенных секторов в SMART. В этом случае еще не все потеряно, но это выходит за рамки данной статьи.
Итак, используя данные SMART даже не нося диск в мастерскую можно довольно точно сказать, что с ним происходит. Существуют различные технологии-надстройки над SMART, которые позволяют определить состояние диска еще более точно и практически достоверно причину его неисправности. Об этих технологиях мы поговорим в отдельной статье.
Нужно знать, что приобретения накопителя со SMART не достаточно, для того, что бы быть в курсе всех происходящих с диском проблем. Диск, конечно, может следить за своим состоянием и без посторонней помощи, но он не сможет сам предупредить в случае приближающейся опасности. Нужно что-то, что позволит на основании данных SMART выдать предупреждение. (обычная цепочка приведена на рисунке чуть ниже).
Как вариант возможен BIOS, который при загрузке при включенной соответствующей опции проверяет состояние SMART накопителей. А если же вам хочется вести постоянный контроль за состоянием диска, необходимо использовать какую-то программу мониторинга. Тогда вы сможете видеть информацию в подробном и удобном виде.

SmartMonitor из HDD Speed работающий под DOS

SIGuiardian, работающая из Windows
Об этих программах мы также поговорим в отдельной статье. Именно это я имел ввиду, когда говорил о том, что по началу не выполнялись необходимые требования при эксплуатации жестких дисков с SMART .
Технологии хранения информации:
Технология NoiseGuardMагнито-оптические технологии
Технология S.M.A.R.T. родилась в далеком 1995 году, так что возраст у нее почтенный. Предполагалось, что атрибуты SMART (давайте для простоты писать аббревиатуру без точек), формируемые микропрограммой жесткого диска, позволят программно оценивать состояние накопителя, а также дадут механизм для предсказания выхода его из строя. Последнее в те времена было достаточно актуально: срок жизни дисков в серверах, например, исчислялся годом-полутора, и знать, когда готовить замену, было нелишним.
Со временем многое поменялось: что-то отмерло, какие-то стороны развились сильнее (например, контроль механики диска). Первоначальный набор из десятка простейших атрибутов усложнился и разросся в несколько раз, порой менялся их смысл, многие производители ввели собственные атрибуты с не всегда ясным функционалом. Появилась масса программ для анализа SMART (как правило, невысокого качества, но с эффектным интерфейсом, да еще и за деньги) и т.п.
Так что не мешает описать современное состояние SMART. Начнем с критически важных атрибутов, ухудшение которых почти всегда свидетельствует о проблемах с накопителем. Именно их первым делом смотрят ремонтники при диагностике HDD.
- #01 Raw Read Error Rate — частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска. Для всех дисков Seagate, Samsung (семейства F1 и более новые) и Fujitsu 2,5″ это — число внутренних коррекций данных, проведенных ДО выдачи в интерфейс; на пугающе огромные цифры можно не обращать внимания.
- #03 Spin-Up Time — время раскрутки пакета пластин из состояния покоя до рабочей скорости. Растет при износе механики (повышенное трение в подшипнике и т.п.), также может свидетельствовать о некачественном питании (например, просадке напряжения при старте диска).
- #05 Reallocated Sectors Count — число операций переназначения секторов. Когда диск обнаруживает ошибку чтения/записи, он помечает сектор переназначенным и переносит данные в резервную область. Вот почему на современных HDD нельзя увидеть bad-блоки — все они спрятаны в переназначенных секторах. Этот процесс называют remapping, на жаргоне — ремап. Поле Raw Value атрибута содержит общее количество переназначенных секторов. Чем оно больше, тем хуже состояние поверхности диска.
- #07 Seek Error Rate — частота ошибок при позиционировании блока магнитных головок (БМГ). Рост этого атрибута свидетельствует о низком качестве поверхности или о поврежденной механике накопителя. Также может повлиять перегрев и внешние вибрации (например, от соседних дисков в корзине).
- #10 Spin-Up Retry Count — число повторных попыток раскрутки дисков до рабочей скорости в случае, если первая попытка была неудачной. Если значение атрибута растет, то велика вероятность проблем с механикой.
- #196 Reallocation Event Count — число операций переназначения. В поле Raw Value атрибута хранится общее число попыток переноса информации со сбойных секторов в резервную область диска (она, как правило, не слишком велика — несколько тысяч секторов). Учитываются как успешные, так и неудачные операции.
- #197 Current Pending Sector Count — текущее число нестабильных секторов. Здесь хранится число секторов, являющихся кандидатами на замену. Они не были еще определены как плохие, но считывание с них происходит с затруднениями (например, не с первого раза). Если «подозрительный» сектор будет в дальнейшем считываться успешно, то он исключается из числа кандидатов. В случае же повторных ошибочных чтений накопитель попытается восстановить его и выполнить ремап.
- #198 Uncorrectable Sector Count — число секторов, при чтении которых возникают неисправимые (внутренними средствами) ошибки. Рост этого атрибута указывает на серьезные дефекты поверхности или на проблемы с механикой накопителя.
- #220 Disk Shift
— сдвиг пакета пластин относительно оси шпинделя. В основном возникает из-за сильного удара или падения диска. Единица измерения неизвестна, но при сильном росте атрибута диск не жилец.
Также следует принимать во внимание и информационные атрибуты , способные много чего поведать об «истории» диска.
- #02 Throughput Performance — средняя производительность диска. Если значение атрибута уменьшается, то велика вероятность, что у накопителя есть проблемы.
- #04 Start/Stop Count — число циклов запуск-остановка шпинделя. У дисков некоторых производителей (например, Seagate) — счетчик включения режима энергосбережения.
- #08 Seek Time Performance — средняя производительность операции позиционирования головок. Снижение значения этого атрибута свидетельствует о неполадках в механике привода головок (в первую очередь о замедленном позиционировании).
- #09 Power-On Hours (POH) — время, проведённое во включенном состоянии. Показывает общее время работы диска, единица измерения зависит от модели (не только 1 час, но и 30 мин, и даже 1 минута).
- #11 Recalibration Retries — число повторов рекалибровки в случае, если первая попытка была неудачной. Рост этого атрибута указывает на проблемы с механикой диска.
- #12 Device Power Cycle Count — число полных циклов включения-выключения диска.
- #13 Soft Read Error Rate — частота появления «программных» ошибок при чтении данных. Сюда можно отнести ошибки программного обеспечения, драйверов, файловой системы, неверную разметку диска — в общем, почти все, что не относится к аппаратной части.
- #190 Airflow Temperature — температура воздуха внутри корпуса HDD. Для дисков Seagate атрибут выдается в нормировке 100º минус температура (тем самым критический нагрев соответствует значению 45), а модели Western Digital используют нормировку 125º минус температура.
- #191 G - sense error rate — число ошибок, возникших из-за внешних нагрузок. Атрибут хранит показания встроенного акселерометра, который фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера.
- #192 Power - off retract count — число зафиксированных повторов включения/выключения питания накопителя.
- #193 Load/Unload Cycle Count — число циклов перемещения БМГ в специальную парковочную зону/в рабочее положение.
- #194 HDA temperature — температура механической части диска, в просторечии банки (HDA — Hard Disk Assembly). Информация снимается со встроенного термодатчика, которым служит одна из магнитных головок, обычно нижняя в банке. В битовых полях атрибута фиксируются текущая, минимальная и максимальная температура. Не все программы, работающие со SMART, правильно разбирают эти поля, так что к их показаниям стоит относиться критично.
- #195 Hardware ECC Recovered — число ошибок, скорректированных аппаратной частью диска. Сюда входят ошибки чтения, ошибки позиционирования, ошибки передачи по внешнему интерфейсу. На дисках с SATA-интерфейсом значение нередко ухудшается при повышении частоты системной шины — SATA очень чувствителен к разгону.
- #199 UltraDMA (Ultra ATA) CRC Error Count — число ошибок, возникающих при передаче данных по внешнему интерфейсу в режиме UltraDMA (нарушения целостности пакетов и т.п.). Рост этого атрибута свидетельствует о плохом (мятом, перекрученном) кабеле и плохих контактах. Также подобные ошибки появляются при разгоне шины PCI, сбоях питания, сильных электромагнитных наводках, а иногда и по вине драйвера.
- #200 Write Error Rate/ Multi-Zone Error Rate — частота появления ошибок при записи данных. Показывает общее число ошибок записи на диск. Чем больше значение атрибута, тем хуже состояние поверхности и механики накопителя.
Как видим, большинство «интересных» атрибутов отражает функционирование механики накопителя. Технология SMART действительно позволяет предсказывать выход диска из строя в результате механических неисправностей, что, по статистике, составляет около 60% всех отказов. Полезен и мониторинг температур: перегрев головок резко ускоряет их деградацию, так что превышение опасного порога (45-55º в зависимости от модели) — сигнал срочно улучшить охлаждение диска.
Вместе с тем не следует переоценивать возможности SMART. Современные диски нередко «дохнут» на фоне отличных атрибутов, что связано с тонкими процессами дефект-менеджмента в условиях высокой плотности записи и не всегда, мягко говоря, качественных компонентов (разнобой в отдаче головок сегодня — обычное дело). Тем более SMART не способен предсказать последствия таких «форс-мажоров», как скачок напряжения, перегрев платы электроники или повреждение накопителя от удара.
Практически у всех атрибутов наибольший интерес представляет поле Raw Value: «сырые» значения наиболее информативны. Их нормировка (степень приближения к абстрактному порогу) часто ничего не дает и только запутывает дело. Поэтому и программы, полагающиеся на эти проценты, нельзя считать вполне надежными. Типичный случай для них — ложные тревоги. Программа сообщает, что новый, недавно установленный накопитель того и гляди «склеит ласты». А все дело в том, что в начале эксплуатации некоторые атрибуты SMART быстро меняются и примитивная экстраполяция приводит к пугающим пользователя прогнозам.
Я советую бесплатную программу HDDScan— она корректно понимает все атрибуты, в том числе и новые, правильно разбирает температурные показатели. Отчет выводится в виде аккуратной xml-таблицы с цветовой индикацией, которую можно сохранить или распечатать.
SMART диска WD пятилетнего возраста. О его близкой кончине свидетельствуют ненулевые значения атрибутов 1 и 200 (для WD они особенно чреваты), а также тот факт, что после ремапа атрибут 197 снова растет. Это значит, что возможности исправления дефектов исчерпаны
Крайне полезна у HDDScan возможность считывать SMART у внешних накопителей, столь распространенных сегодня. Практически ни одна другая программа этого не умеет, ведь на пути данных стоит контроллер, преобразующий интерфейс PATA/SATA в USB или FireWire. Автор целенаправленно работал в этом направлении, и ему удалось охватить широкий спектр контроллеров. Не забыты и диски с интерфейсом SCSI, до сих пор широко применяемые в серверах (атрибуты у них особые — например, выводится общее число записанных или считанных байтов за всю жизнь накопителя).
Функционал HDDScan полностью отвечает потребностям ремонтника. Когда первичную диагностику принесенного внешнего диска можно провести, не разбирая корпус, — это удобно, экономит время, а порой и сохраняет гарантию.

SMART, снятый со SCSI-диска. Здесь исторически сложились совсем другие атрибуты
⇡ Барьеры HDD
Механика давно стала ахиллесовой пятой HDD, и даже не столько из-за чувствительности к ударам и вибрации (это еще можно компенсировать), сколько из-за медлительности. Самые быстрые «дерганья» блоком магнитных головок (2-3 мс у лучших серверных моделей) в тысячи раз уступают скоростям электроники.
И принципиально ничего тут не улучшишь. Поднимать скорость вращения пакета дисков некуда, 15000 об./мин уже предел. Японцы несколько лет назад подступались к 20000 об./мин (вполне гироскопная скорость), но в итоге отказались — не выдерживают материалы, конструкция получается слишком дорогая и для массового производства слабо пригодная. В малых же сериях винчестеры выйдут золотыми, такие никто не купит — это не гироскопы, которые заменить нечем.
Выходит, уткнулись в барьер. Механику на кривой козе не объедешь. Единственный выход — поднимать плотность записи, поперечную и продольную. Продольная плотность (вдоль дорожки) влияет на производительность накопителя, т.е. на поток данных к остальным узлам компьютера. Но все равно, даже достигнутые 100-130 Мбайт/с — это для нынешних компьютеров слишком мало. Например, рядовая оперативная память (DRAM) имеет реальную производительность около 3 Гбайт/с, а кеш процессора — еще больше. Разница на порядки, и она сильно сказывается на общем быстродействии. Конечно, никто не требует от энергонезависимого накопителя, емкость которого в сотни раз превышает DRAM, такой же производительности. Но даже простое удвоение было бы заметно любому пользователю.
Поперечная плотность записи — это густота дорожек на пластине, в современных HDD она превышает 10000 на 1 миллиметр. Получается, что сама дорожка имеет ширину менее 100 нм (между прочим, нанотехнологии в чистом виде). Это позволяет резко поднять емкость в расчете на одну поверхность, а также ускоряет позиционирование за счет изощренных алгоритмов (их разработка потянула бы на пару докторских диссертаций).
Как итог, за последние годы емкость и производительность HDD значительно выросли. Все это стало возможным благодаря технологии перпендикулярной записи, которая существует уже более 20 лет, но до массового внедрения дозрела только в 2007 году. Причем емкость тогда выросла даже сильнее, чем требуется: первые терабайтные диски встретили вялый отклик пользователей. Народ просто не понимал, куда приспособить таких монстров, тем более что они поначалу строились на пяти пластинах, были капризными, шумными и горячими (речь о тогдашних флагманах Hitachi).
Потом, конечно, люди разобрались, торренты заработали в полную силу, да и количество пластин поуменьшилось. В то же время плотность записи выросла до 500-750 Гбайт на пластину (имеются в виду диски настольного сегмента с форм-фактором 3,5″). Вот-вот в массовое производство пойдут терабайтные пластины, что даст возможность выпустить винчестеры объемом до 4 Тбайт (больше четырех пластин в стандартном корпусе высотой 26,1 мм не уместить; хитачевские пятипластинные первенцы большого развития не получили).

Трехтерабайтный диск WD Caviar Green WD30EZRX, наиболее емкий на сегодня. Имеет четырехпластинный дизайн, выпускается ровно год (с 20 октября 2010 г.). Как полагается, весной и летом дешевел, но в последние дни резко подорожал из-за наводнения в Таиланде (там расположены сборочные заводы WD, и стихия блокировала подвоз комплектующих)
Увы, скорость позиционирования выросла, мягко говоря, несильно, а у массовых моделей так вообще осталась на прежнем уровне, а то и упала в угоду… тишине. Маркетологи доказали, что потребитель голосует кошельком за гигабайты в расчете на один доллар, а не за миллисекунды доступа. Поэтому и небыстры дешевые диски по сравнению с породистыми серверными собратьями. Медлительность хорошо проявляется в скорости загрузки ОС, когда надо читать с диска большое количество мелких файлов, разбросанных по пластинам. Здесь главную роль играет скорость вращения шпинделя и мощный привод БМГ, дающий возможность больших ускорений.
Между прочим, «быстрые» диски легко отличить даже на вес — они заметно тяжелее «медленных». Полноразмерная банка с утолщенными стенками, способствующая геометрической стабильности и подавлению вибраций, скоростной шпиндельный двигатель, мощные магниты позиционера, двухслойная крышка повышенной жесткости — все это прибавляет такому накопителю десятки и сотни граммов. Еще больше отрыв в серверных моделях на 15000 об./мин, где пластины уменьшенного размера окружены внушительным объемом литого алюминия, а общий вес «харда» доходит до килограмма.

Высокопроизводительный диск WD Raptor со скоростью вращения шпинделя 10 000 об./мин. При емкости 150 Гбайт весит 740 г (массовые модели той же емкости — 400-500 г). Обратите внимание на размер магнитов и толщину стенок
С удешевлением твердотельных SSD, использующихся, в первую очередь, под операционную систему, нужда в высокопроизводительных HDD стала снижаться, а сами они постепенно выделяются в особый сегмент рынка (такова, например, «черная» серия у WD). Подобными дисками комплектуются профессиональные рабочие станции с ресурсоемкими приложениями, критичными к скорости доступа. Рядовые же пользователи брать достаточно дорогие накопители не торопятся, предпочитая объем производительности.
На другом конце спектра — популярные «зеленые» модели с намеренно замедленным вращением шпинделя (5400-5900 об./мин вместо 7200) и небыстрым позиционированием головок. Дешевые, тихие, холодные и достаточно надежные, эти винчестеры идеально подходят для хранения мультимедийных данных в домашних компьютерах, внешних корпусах и сетевых хранилищах. На наших прилавках все эти Green и LP сильно потеснили другие линейки, так что в мелких «точках» порой ничего больше и не найдешь.
⇡ Расточительность магнитной записи
Намагниченность доменов жесткого диска, как и в середине двадцатого века, меняют с помощью магнитной головки, поле которой возбуждается переменным электрическим током и действует на магнитный слой через зазор. Также эта технология требует быстрого вращения пластин, прецизионного контроля положения головки и т.д. Двигатель и позиционер жесткого диска, а также управляющая ими электроника потребляют заметную мощность, да и стоят немало. Но главное — на само возбуждение магнитного поля тратится очень много энергии.
Расточительность стандартного метода магнитной записи трудно оценить, работая на персональном компьютере. Жесткие диски массовых серий даже при активной работе потребляют менее 10 Вт, что на фоне прочих комплектующих (100 Вт и более) почти незаметно. Но ваши взгляды сразу переменятся после посещения серверной комнаты какого-нибудь крупного банка, а чтобы получить впечатлений на всю оставшуюся жизнь, достаточно подойти к дисковой стойке суперкомпьютера. В шуме сотен и тысяч жестких дисков, обдувающих их вентиляторов и прецизионных кондиционеров становится понятно, сколько энергии в глобальном масштабе тратится на такую работу.
Недаром для систем хранения данных энергоэффективность в списке характеристик выходит на первый план. Вот уже и Google переводит свои дата-центры на баржи в море (вот где настоящие офшоры!). Оказывается, охлаждение СХД забортной водой радикально сокращает операционные затраты, в первую очередь за счет экономии на кондиционерах.
⇡ О питании жестких дисков
Будет ли работать обычная 220-вольтовая лампочка от 230 В? Конечно, будет. А от 240 В? Тоже. Вопрос — сколько она протянет? Понятно, что меньше или существенно меньше — это зависит от конкретной лампочки. Ей суждена яркая, но короткая жизнь.
Примерно та же ситуация и с жесткими дисками. Наивные производители проектировали их, полагаясь на стандартные +5 В и +12 В. Однако в типичном компьютерном блоке питания (БП) стабилизируется лишь линия 5 В. К чему же это приводит?
При высокой нагрузке на процессор (а современные «камни» потребляют немало) и недостаточной мощности БП линия 5 В проседает, и система стабилизации отрабатывает это дело, повышая напряжение до номинального значения. Одновременно повышается и напряжение 12 В (из-за отсутствия стабилизации по нему). В результате и так нестойкий к нагреву HDD работает еще и при повышенном напряжении, которое подается на самые греющиеся узлы — микросхему управления двигателем (на жаргоне ремонтников — «крутилка») и привод головок (т.н. «звуковая катушка»). Итог — смотри рассуждение о лампочке.


Сгоревшая «крутилка» на плате как результат повышенного напряжения и плохого охлаждения. Нередко микросхема сгорает в буквальном смысле, с пиротехническими эффектами и выгоранием дорожек на плате. Такое ремонту не подлежит
Отсюда советы по блоку питания. Чем больше его мощность, тем лучше (в разумных пределах: запас более 30-35% по отношению к реальному потреблению снижает КПД блока, так что вы будете греть комнату). Менее мощный, но фирменный БП лучше более мощного, но безродно-китайского. Помните — разгоняют не только процессоры. В первом приближении, 420 «китайских» ватт эквивалентны 300 «правильным».
По-хорошему, надо бы еще учитывать возраст БП: после 2-3 лет эксплуатации его реальная мощность заметно снижается, а выходные напряжения дрейфуют. Разумеется, в некачественных изделиях, работающих на честном китайском слове, процессы старения выражены гораздо резче. Хорошо еще, если подобный блок тихо умрет сам, а не утащит за собой в агонии половину системного блока!
Максимально допустимым считается 12,6 В (+5% от номинала). Однако у многих дисков c ростом напряжения наблюдается нелинейно-резкий нагрев упомянутых выше узлов — «крутилки» и «катушки». Поэтому я рекомендую строже контролировать БП с помощью внешнего вольтметра (датчики на материнской плате, измеряющие напряжение для BIOS и программ типа AIDA, могут быть весьма неточны).
Измерять напряжение лучше всего на разъемах Molex и обязательно под полной нагрузкой: процессор занят вычислениями с плавающей точкой, видеокарта — выводом динамичной трехмерной графики, а диск — дефрагментацией. При 12,2-12,4 В стоит призадуматься, 12,4-12,6 В — поволноваться, 12,6-13 В — бить тревогу, а в случае 13 В и выше — копить деньги на новый диск или положить гарантийный талон на видное место…

Конденсаторы (2200 мкФ, 25 В), напаянные на цепи питания HDD (желтый провод — +12 В, красный — +5 В, черный — земля). В данном случае они уменьшают пульсации напряжения, от которых блок питания издает раздражающий высокочастотный писк
Если напряжение по линии 12 В сильно завышено, а вы не боитесь паяльника и способны отличить транзистор от диода, то можете включить последний в разрыв питания HDD (напомню, линии 12 В соответствует желтый провод). Диод сыграет роль ограничителя — на его p-n переходе упадут «лишние» 0,2-0,7 В (в зависимости от типа диода), и диску станет полегче. Только диод надо брать достаточно мощный, чтобы он выдерживал пусковой ток в 2-3 А.
И без фанатизма: результирующее напряжение не должно опускаться ниже 11,7 В. В противном случае возможна неустойчивая работа диска (множественные рестарты) и даже порча данных. А некоторые модели (в частности, Seagate 7200.10 и 7200.11) могут вообще не запуститься.
⇡ Миграция с флеш
Память NAND Flash появилась много позднее, чем HDD, и переняла ряд его технологий — взять хотя бы коды ECC. Далее оба направления развивались параллельно и сравнительно независимо. Но в последнее время наметился и обратный процесс: миграция технологий с флеш-памяти на жесткие диски. Конкретно речь идет о выравнивании износа.
Как известно, любой флеш-чип имеет ограниченный ресурс по числу стираний-записей в одну ячейку. В какой-то момент стереть ее уже не удается, и она навсегда застывает с последним записанным значением. Поэтому контроллер считает количество записей в каждую страницу и в случае превышения копирует ее на менее изношенное место. В дальнейшем вся работа ведется с новым участком (этим заведует транслятор), а старая страница остается как есть и не используется. Данная технология получила название Wear Leveling. Так вот, износ есть и в жестких дисках, но там он механический и температурный. Если магнитная головка все время висит над одной дорожкой (скажем, постоянно изменяется тот или иной файл), то растет вероятность повреждения дорожки при случайных толчках или вибрации диска (например, от соседних накопителей в корзине). Головка может коснуться пластины и повредить магнитный слой со всеми вытекающими печальными последствиями. Даже если вредного контакта нет, неподвижная головка локально нагревается и пусть обратимо, но деградирует. Запись в данное место происходит менее надежно, растет вероятность последующего неустойчивого считывания (а при современных огромных плотностях записи любое отклонение параметров губительно).
Эти соображения достаточно очевидны, и прошивка серверных дисков с интерфейсом SCSI/SAS (а они весьма горячи) давно научилась перемещать головки в простое, дабы они не перегревались. Но еще лучше вместе с головкой «перебрасывать» и информацию по пластине — в этом случае описанные эффекты подавляются максимально, а надежность накопителя растет. Вот Western Digital и ввел подобный механизм в новых моделях VelociRaptor. Это дорогие высокопроизводительные диски со скоростью вращения шпинделя 10000 об./мин и пятилетней гарантией, так что Wear Leveling там уместен.


VelociRaptor снаружи и внутри. Привлекает внимание мощный радиатор. Пластины же имеют уменьшенный диаметр — это характерно для современных скоростных дисков.
Кроме того, вся линейка VelociRaptor нацелена на использование в высоконагруженных системах, в первую очередь серверах, где запись на диск ведется очень интенсивно и зачастую в одни и те же файлы (типичный пример — логи транзакций). Массовым «ширпотребным» дискам высокие нагрузки не грозят, греются они тоже умеренно, так что подобный изыск там вряд ли появится. Впрочем, поживем — увидим.
⇡ Аdvanced Format и его применение
Вот уже более 20 лет все жесткие диски имеют одинаковый размер физического сектора: 512 байт. Это минимальная порция записи на диск, позволяющая гибко управлять распределением дискового пространства. Однако с ростом объема HDD все сильнее стали проявляться недостатки такого подхода — в первую очередь неэффективное использование емкости магнитной пластины, а также высокие накладные расходы при организации потока данных.
Поэтому диски большой емкости (терабайт и выше) стали производиться по технологии Advanced Format , которая оперирует «длинными» физическими секторами в 4096 байт. Разметка магнитных пластин под AF весьма выгодна для производителя: меньше межсекторных промежутков, выше полезная емкость дорожки и всей пластины (а это, наряду с магнитными головками, самый дорогой компонент HDD). Именно Advanced Format позволил выпустить на рынок недорогие винчестеры, столь популярные ныне у потребителей аудио- и видеоконтента. AF-дисками емкостью 1-3 Тбайт комплектуются не только компьютеры, но и масса внешних накопителей, сетевых хранилищ и медиаплееров.

Один из первых дисков 3,5″ с Advanced Format, выпущенный в 2009 г
Но даром ничего не дается, новые диски уже начинают приносить в ремонт. Похоже, надежность все-таки просела. Ведь единичный сбой диска или дефект поверхности портит теперь в 8 раз больше данных пользователя, чем обычно. При физическом секторе в 4 Кбайт и эмуляции «коротких» секторов в 512 байт не будет читаться от 1 до 8 секторов. Операционная система на это реагирует понятно как: авария, все пропало! В итоге мелкая проблема на пластинах вырастает для пользователя в зависание или чего еще хуже.
Я считаю, на дисках с AF не стоит держать ОС, прикладные программы и базы данных со множеством мелких файлов. Пока что их удел — мультимедийные данные, некритичные к выпадениям.
В первую очередь рекомендую заглянуть на форум HARDW.net . Его раздел «Накопители информации» посещает множество профессиональных ремонтников и энтузиастов (почти 40 тыс. участников). Там можно найти ответы практически по любой теме, связанной с HDD, за исключением самых новых «нераскопанных» моделей. Начните с подраздела «Песочница»: на простые (в понимании профессионалов) вопросы там отвечают подробно и содержательно, а не отшивают, как в других местах, — «несите к ремонтнику».
Еще больше информации, правда, на английском языке, можно найти на портале HDDGURU . Помимо ремонтно-диагностического ПО и статей по отдельным вопросам (например, как поменять головки у диска), там есть международный форум ремонтников, а также огромный архив ресурсов по HDD (firmware, документация, фото и т.п.). Портал прививает широкий взгляд на вещи, он будет интересен подготовленным и мотивированным людям. Во всяком случае, в закрытых конференциях ремонтников ссылки на него пробегают постоянно.
Сошлюсь и на свою статью «Как продлить жизнь жестким дискам» в трех частях. Она дает начальные сведения по обращению с HDD, и хотя написана более трех лет назад, устарела мало — диски за это время принципиально не изменились, разве что стали еще менее надежными из-за свирепой экономии. Производители, застигнутые мировым кризисом, снижали свои затраты по всем направлениям, что и послужило причиной ряда громких провалов 2008-2009 гг. Об одном из них речь пойдет в продолжении этого материала, которое выйдет в ближайшее время.