میکروفون گفتار را تشخیص نمی دهد. موتور تشخیص گفتار گفتار را تشخیص نمی دهد
ویندوز تشخیص گفتار مبتنی بر دستگاه (از طریق Windows Recech Recognition Desktop قابل دسترسی است) و تشخیص گفتار مبتنی بر ابر در بازارها و مناطقی که کورتانا در دسترس است را فراهم می کند. مایکروسافت ممکن است از داده های صوتی ، تعاملات رایانه ای برای بهبود خدمات تشخیص گفتار استفاده کند.
برای استفاده از تشخیص گفتار ، باید Meet You (تنظیمات حریم خصوصی تحت Personalize Handwriting and Keyboard Input) را روشن کنید زیرا سرویس های صوتی هم در cloud و هم در دستگاه شما وجود دارند. اطلاعاتی که مایکروسافت از طریق آنها جمع می کند به ما در بهبود آنها کمک می کند. سرویس های گفتاری که به فضای ابری پخش نمی شوند و فقط در دستگاه شما وجود دارند ، مانند Announcer و Windows Speech Recognition ، اگر این تنظیمات غیرفعال باشد ، همچنان کار خواهند کرد ، اما Microsoft دیگر داده ها را جمع نمی کند.
اگر عیب یابی و استفاده از داده (گزینه ها → حریم خصوصی → عیب یابی و بازخورد) روی حالت کامل تنظیم شود ، ورودی جوهر و متن به مایکروسافت ارسال می شود و شرکت به طور کلی از این داده ها استفاده می کند تا بستر را برای همه کاربران بهبود بخشد.
برای خاموش کردن تشخیص صدا در ویندوز 10 ، این مراحل را دنبال کنید.
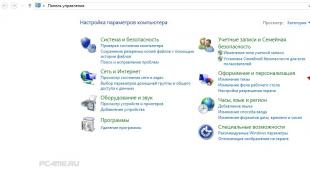
- برنامه را باز کنید "مولفه های".
- رفتن به بخش "حریم خصوصی" "توابع صوتی".
- در سمت راست ، گزینه را غیرفعال کنید "تشخیص صدا در شبکه"با حرکت دادن نوار لغزنده سوئیچ به موقعیت "خاموش".
عملکرد اکنون غیرفعال شده است.
متناوباً ، می توانید تنظیمات رجیستری را اعمال کنید.
با استفاده از تنظیمات رجیستری ، تشخیص گفتار آنلاین را غیرفعال کنید.
- بایگانی ZIP زیر را بارگیری کنید: بایگانی zip را بارگیری کنید.
- محتویات آن را به هر پوشه ای استخراج کنید. می توانید پرونده ها را مستقیماً روی دسک تاپ خود قرار دهید.
- روی پرونده دوبار کلیک کنید تشخیص غیر آنلاین .regبرای شروع روند ادغام
برای لغو تغییر در صورت لزوم ، از پرونده استفاده کنید تشخیص گفتار بصورت آنلاین .reg.
پرونده های رجیستری بالا کندوی رجیستری را اصلاح می کنند
HKEY_CURRENT_USER \ نرم افزار \ Microsoft \ Speech_OneCore \ تنظیمات \ OnlineSpeechPrivacy
آنها پارامتر DWORD (32 بیتی) به نام را تغییر می دهند پذیرفته شده است.
- HasAccepted = 1 - تشخیص گفتار را در شبکه فعال کنید.
- HasAccepted = 0 - تشخیص گفتار غیرفعال است.
علاوه بر این ، با شروع ویندوز 10 ساخت 17063 ، سیستم عامل دارای تعدادی تنظیمات جدید در بخش حریم خصوصی است. این موارد شامل توانایی مدیریت مجوزهای استفاده برای کتابخانه ها / پوشه ها ، میکروفون ، تقویم ، اطلاعات حساب کاربر ، سیستم فایل ، موقعیت مکانی ، مخاطبین ، سابقه تماس ، ایمیل ، پیام رسانی و موارد دیگر است.
سرانجام ، می توانید در هنگام نصب سیستم عامل خراش ، تشخیص گفتار آنلاین را از صفحه Privacy Setup Windows خاموش کنید.
ویندوز ویستا اولین سیستم عامل مایکروسافت است که دارای گفتار داخلی است. با استفاده از این عملکرد می توانید کارهای مختلفی مانند راه اندازی برنامه ها ، بستن ، ذخیره و حذف پرونده ها ، نوشتن متن را که به صورت کلمه به کل ضبط می شود و همچنین ویرایش آن را با صدای خود انجام دهید. Deb Shinder ، مشاور فناوری اطلاعات ، نحوه استفاده از این ویژگی را با جزئیات به شما می گوید.
از زمان اکران فیلم Star Trek ، بسیاری از کاربران رایانه آرزو داشته اند که صفحه کلید ، موش و کنترل صوتی رایانه خود را به بیرون پرتاب کنند. برنامه هایی که به شما امکان می دهد با دستورات مختلف صحبت کنید ، متن را به رایانه دیکته می کنید سالهاست که ساخته شده اند و برای کسانی که از نظر جسمی قادر به استفاده از روشهای ورودی دیگر نبودند بسیار مفید بودند. اما بنا به دلایلی ، این برنامه ها محبوب نبودند.
ویندوز ویستا اولین سیستم عامل مایکروسافت است که می تواند گفتار را تشخیص دهد. پیش از این ، تشخیص گفتار در Microsoft Office XP و Office 2003 در دسترس بود و می توان از نرم افزار شخص ثالث مانند Dragon NaturallySpeaking استفاده کرد. مایکروسافت همچنین تشخیص گفتار را به ویندوز موبایل اضافه کرد.
برای شروع صحبت با رایانه خود نیازی به خرید چیز اضافی نیستید ، ویستا همه چیز را برای آن فراهم کرده است. این ویژگی به طور پیش فرض خاموش است ، اما می توانید آن را به راحتی از کنترل پنل راه اندازی کنید ، همانطور که در شکل A نشان داده شده است.
با انتخاب همه برنامه ها | می توانید این عملکرد را از فهرست شروع کنید استاندارد | همه برنامه ها | لوازم جانبی | سهولت دسترسی ، همانطور که در شکل B نشان داده شده است.

چگونه کار می کند
می توانید یکی از دو حالت تشخیص گفتار را انتخاب کنید:
- برای مدیریت برنامه ها: برنامه ها را شروع و بسته کنید ، بین آنها جابجا شوید ، پرونده ها را ذخیره و حذف کنید و غیره.
- برای نوشتن متن ضبط شده کلمه به کلمه ، و همچنین ویرایش آن.
توسعه دهندگان نرم افزار می توانند پشتیبانی از این ویژگی را به برنامه های خود اضافه کنند. شرم آور است که در حال حاضر تشخیص گفتار فقط از چند زبان پشتیبانی می کند: انگلیسی (ایالات متحده و انگلستان) ، آلمانی ، فرانسوی ، اسپانیایی ، ژاپنی و چینی (سنتی و ساده).
تنظیم تشخیص گفتار
قبل از استفاده از تشخیص گفتار ، باید این مراحل را دنبال کنید:
- تشخیص گفتار را روشن کنید.
- میکروفن خود را تنظیم کنید.
- کتابچه راهنما را بخوانید (اختیاری)
- واضح تمرین کنید ، صحبت کنید (همچنین اختیاری است).
پس از دوبار کلیک بر روی Speech Recognition در کنترل پنل یا انتخاب Speech Recognition از منو ، یک پنجره پیکربندی به شما نمایش داده می شود که در شکل C نشان داده شده است.

وقتی روی Start Speech Recognition کلیک می کنید ، یک صفحه کنترل صدا در بالای صفحه شما ظاهر می شود ، همانطور که در شکل D نشان داده شده است.

اگر قبلاً این عملکرد را پیکربندی کرده باشید ، پانل در شروع خودکار ثبت می شود و هر بار بوت شدن ویندوز راه اندازی می شود. یک نماد کنترل صدای آبی نیز در سینی ظاهر می شود.
همانطور که در شکل E نشان داده شده است ، می توانید با کلیک راست روی نماد سینی یا روی صفحه کنترل صدا ، منوی زمینه را برای تنظیمات ظاهر کنید.

در منو ، تنظیمات زیر را مشاهده خواهید کرد:
- روشن کردن سخنرانی:رایانه به هرچه شما بگویید گوش می دهد و دستوراتی را که تشخیص می دهد اجرا می کند.
- خواب:رایانه گفتار شما را کنترل می کند ، اما تا زمانی که نگویید "شروع به گوش دادن" به هیچ فرمانی پاسخ نمی دهد.
- خاموش:رایانه هرچه به او بگویید به شما گوش نمی دهد.
- کارت مرجع گفتار باز را باز کنید:یک برگه تقلب مفید با دستورات اساسی و اطلاعات اضافی.
- شروع آموزش گفتار:آموزش تصویری که به شما گفته می شود و همه چیز به شما نشان داده می شود.
- کمک:یک فایل راهنما درباره این عملکرد باز می کند.
- گزینه ها:در اینجا می توانید برنامه را بارگیری کنید تا همراه با ویندوز ، تصحیح خودکار متن و غیره بارگیری شود.
- پیکربندی:اینجاست که می توانید میکروفن خود را شخصی سازی کنید ، تشخیص گفتار را بهبود ببخشید و صفحه کنترل را باز کنید.
- واژه نامه گفتار را باز کنید:شما می توانید کلمات جدیدی اضافه کنید (برای نام ها و کلماتی که تشخیص آنها دشوار است بسیار مفید است) ، همچنین می توانید کلماتی را که هرگز صحبت نمی کنید حذف کنید.
- موضوع دیکته:فقط روایت را می توان در اینجا انتخاب کرد.
- به سایت بروید (به وب سایت گفتار مراجعه کنید).
- درباره شناخت گفتار اطلاعات کسب کنید:این یک کادر محاوره ای ویندوز است ، که در آن نسخه ، شماره مجوز و نام برنامه نوشته شده است.
- تشخیص گفتار باز (تشخیص گفتار باز).
- خروج:برنامه را کاملاً می بندد.
کنترل صفحه لمسی اکنون استاندارد است. جدیدترین سیستم ها مانند ویندوز 8 دستورات صوتی را "درک" می کنند. تشخیص گفتار باید ارتباط ما با کامپیوتر را حتی ساده تر ، بصری تر و ... طبیعی تر کند. من به شما خواهم گفت که در حال حاضر چگونه به نظر می رسد.
کمی از تاریخچه - چگونه ارتباط با ماشین توسعه یافته است
راه های برقراری ارتباط با کامپیوتر در طول سال ها پیشرفت کرده است. اولین رابطی که از طریق آن شخص می تواند دستورات را بدهد کارت های پانچ است که مربوط به سال 1832 است. از آنها در ماشین آلات پارچه سازی استفاده می شد. صفحه کلید برای اولین بار در سال 1960 استفاده شد. دو دهه بعد ، موش استاندارد متصل شد و امروزه نیز مورد استفاده قرار می گیرد. اگرچه ماوس با پد لپ تاپ مشترک است ، اما همچنان محبوب ترین نوع کنترل است. به لطف تلفن های هوشمند و تبلت ها ، رابط کاربری لمسی و حرکات بسیار محبوب شده اند که به ویژه برای کنترل Xbox 360 Kinect استفاده می شوند. پس از نمایشگرهای لمسی و حرکات ، کنترل صدا وجود دارد ، اما این راه حل تاکنون آنقدر توسعه نیافته است که حتی گاهی اوقات حتی در مورد آن چیزی نمی شنوید.
پیکربندی تشخیص گفتار در ویندوز 8
متأسفانه ، کنترل صدا هنوز به زبان روسی موجود نیست. در حال حاضر انگلیسی ، فرانسوی ، آلمانی ، ژاپنی ، کره ای ، چینی و اسپانیایی پشتیبانی می شوند. مایکروسافت تصمیم گرفته است که روی بزرگترین و پیشرفته ترین کشورها تمرکز کند ، اما ممکن است مدتی این قابلیت را برای کشور ما اضافه کند. اگر سعی کنید آن را شروع کنید ، اینگونه قسم می خورد
اگر هنوز می خواهید این راه حل را آزمایش کنید ، باید سیستم را پیکربندی کنید (زبان را تغییر دهید) و چند کلمه به انگلیسی یاد بگیرید. برای انجام این کار ، باید به صفحه کنترل بروید و مورد Language را انتخاب کنید. اگر زبانی غیر از روسی ندارید ، باید روی دکمه "افزودن زبان" کلیک کنید و سپس یکی از زبانهای پشتیبانی شده را انتخاب کنید. در مورد ما ، این "انگلیسی (ایالات متحده)" است. ما می بینیم که فقط طرح به این زبان موجود است ، ما دوبار کلیک می کنیم ، این در دسترس بودن زبان رابط را بررسی می کند ، پس از بررسی ، روی "بارگیری و نصب بسته زبان" کلیک می کنیم ، و روند با حوصله ادامه می یابد منتظر بارگیری آن پس از اتمام این روند ، زبان پیش فرض خود را به انگلیسی تنظیم کنید


اکنون باید به صفحه شروع ویندوز 8 بروید (کاشی کاری شده) ، "جستجوی گفتار Windows" را در جستجو وارد کرده و Enter را فشار دهید.

به این ترتیب می توانید ابزار تشخیص صدا را اجرا کنید. در اولین شروع ، میکروفن را پیکربندی کنید ، پس از انتخاب ، چیزی برای بررسی بگویید.


در مرحله بعدی ، پیشنهاد دهید که دوره های آموزشی را بگذرانید. طول آنها تا 15-20 دقیقه است ، اما بسیار مفید هستند و اطلاعات اساسی در مورد استفاده از توابع را ارائه می دهند. اما اگر در زبان انگلیسی قوی نیستید ، فکر می کنم ارزش هدر دادن وقت را ندارد ، ساختن هر چیزی ، بلافاصله وارد جنگ دشوار خواهد بود

چگونگی کار
برای اینکه رایانه شروع به تشخیص گفتار شما کند ، باید بگویید "شروع به گوش دادن" (که به معنی شروع به گوش دادن است) ، یا دکمه میکروفن را فشار دهید تا حالت گوش دادن شروع شود. اکنون می توانید برنامه را باز کنید یا فقط کلمات را به یک ویرایشگر متن ، مرورگر یا نوار جستجو دیکته کنید

چه می توانیم بکنیم
در اصل ، امکانات بسیار زیاد است ، علاوه بر کلمات استاندارد ، می توانید دستورات خود را ایجاد کنید. ویژگی های اصلی در جدول نشان داده شده است
| عمل | چه بگویم |
| هر موردی را به نام خود انتخاب کنید | روی File، Start، View کلیک کنید |
| هر مورد یا نمادی را انتخاب کنید | روی سطل آشغال کلیک کنید ، روی رایانه کلیک کنید ، کلیک کنید (نام پرونده) |
| روی هر مورد دوبار کلیک یا دوبار کلیک کنید | روی Recycle Bin دوبار کلیک کنید ، روی Computer دوبار کلیک کنید |
| بین برنامه های باز جابجا شوید | تغییر به رنگ ، تغییر به WordPad |
|
پیمایش |
بکش بالا؛ پایین بروید ؛ |
|
پاراگراف جدید یا خط جدیدی را در سند وارد کنید |
پاراگراف جدید خط جدید |
|
یک کلمه را در سند انتخاب کنید |
|
|
تصحیح کلمه |
کلمه صحیح |
|
کلمات خاصی را انتخاب و حذف کنید |
|
|
نمایش لیست دستورات قابل اجرا |
|
|
دستورات گفتاری را تازه کنید |
|
|
حالت گوش دادن را روشن کنید |
|
|
حالت گوش دادن را غیرفعال کنید |
|
|
میکروفن را به حداقل برسانید |
تشخیص گفتار را به حداقل برسانید |
|
راهنما و پشتیبانی ویندوز را مشاهده کنید |
چگونه کاری انجام دهم؟ |
اگر نمی دانید چگونه این عبارت را تلفظ کنید ، پیشنهاد می کنم از Google Translate یا http استفاده کنید: //www.tuchilochka.rf (او این سایت را بهتر درک کرده است)
من تمایل داشتم که دستورات خود را متشکل از کلمات ساده بورژوازی بنویسم. که می توانم تلفظ کنم. بنابراین او به من اجازه این کار را نداد ، او نمی توانست ویرایشگر دستور را شروع کند. در نتیجه ، او تلفظ من را از کلمات One، Two و Open کاملاً درک کرد. با استفاده از این مجموعه ، می توانید برنامه را با شماره موجود در صفحه اصلی راه اندازی کنید. ابتدا شماره را بگویید ، سپس بگویید OPEN. البته زیاد نیست ، اما من آزمایش را یک موفقیت می دانم. بد نیست اگر مایکروسافت روسی را جایگزین خوبی برای کنترل از راه دور کرد.
- ترجمه
از زمان ورود یادگیری عمیق به صحنه تشخیص گفتار ، تعداد اشتباهات در تشخیص کلمات به طرز چشمگیری کاهش یافته است. اما با وجود تمام مقالاتی که ممکن است خوانده باشید ، ما هنوز تشخیص گفتار در سطح انسانی نداریم. تشخیص دهنده گفتار انواع مختلفی از خرابی ها را دارد. برای بهبود بیشتر ، آنها باید شناسایی شوند و سعی شوند از بین بروند. این تنها راهی است که می توان از شناختی که بیشتر اوقات برای برخی از افراد کار می کند به شناختی که برای همه افراد تمام وقت کار می کند ، برد.
پیشرفت در تعداد کلمات اشتباه شناسایی شده شماره گیری صوتی آزمایشی در سال 2000 از 40 مکالمه تصادفی بین دو نفر که زبان مادری آنها انگلیسی است ، روی یک سوئیچ تلفنی تنظیم شده است
اینکه بگوییم ما در مکالمه فقط بر اساس مجموعه مکالمه های تابلوی برق به سطح یک فرد در تشخیص گفتار رسیده ایم ، مانند این است که ادعا می کنیم ماشین رباتیک بدتر از یک شخص رانندگی نمی کند ، آن را در یک شهر واحد آزمایش کرده است در یک روز آفتابی و بدون هیچ گونه ترافیکی ... تغییرات اخیر در تشخیص گفتار شگفت انگیز است. اما ادعاهای مربوط به تشخیص گفتار در سطح انسان بسیار پررنگ است. در اینجا چند زمینه وجود دارد که هنوز هم باید پیشرفت هایی انجام شود.
لهجه ها و سر و صدا
یکی از معایب آشکار تشخیص گفتار پردازش است لهجه هاو سر و صدای پس زمینه دلیل اصلی این امر این است که بیشتر داده های آموزش از یک گویش آمریکایی با نسبت سیگنال به نویز بالا تشکیل شده است. به عنوان مثال ، در مجموعه مکالمات سوئیچ تلفنی فقط مکالمه افرادی وجود دارد که زبان مادری آنها انگلیسی است (عمدتا آمریکایی) با سر و صدای کم پس زمینه.اما افزایش داده های آموزش به خودی خود احتمالاً این مشکل را حل نخواهد کرد. زبان های زیادی با بسیاری از گویش ها و لهجه ها وجود دارد. جمع آوری داده های دارای برچسب برای همه موارد غیرواقعی است. ساخت یک تشخیص دهنده گفتار با کیفیت عالی فقط انگلیسی انگلیسی نیاز به حداکثر 5000 ساعت صدا دارد که به متن تبدیل می شود.
مقایسه افرادی که درگیر تبدیل گفتار به متن هستند با گفتار عمیق 2 بایدو در مورد انواع مختلف گفتار. مردم کمتر در تشخیص لهجه های غیر آمریکایی موفق هستند - شاید به دلیل وجود آمریکایی های فراوان در میان آنها. من فکر می کنم افرادی که در یک منطقه خاص بزرگ شده اند ، با اشتباهات بسیار کمتر ، با تشخیص لهجه آن منطقه کنار آمده اند.
در حضور نویز پس زمینه در اتومبیل در حال حرکت ، نسبت سیگنال به نویز می تواند تا 5 دسی بل باشد. در چنین شرایطی افراد به راحتی می توانند با تشخیص گفتار شخص دیگری کنار بیایند. شناسایی کننده های خودکار با افزایش نویز عملکرد را بسیار سریعتر کاهش می دهند. نمودار نشان می دهد که با افزایش نویز (در مقادیر SNR پایین ، نسبت سیگنال به نویز) جدایی افراد چقدر افزایش می یابد
خطاهای معنایی
غالباً ، تعداد واژه های به اشتباه تشخیص داده شده به خودی خود یک سیستم تشخیص گفتار نیست. ما تعداد خطاهای معنایی را هدف قرار داده ایم. این کسری از عبارات است که در آن معنی را اشتباه درک می کنیم.یک مثال از یک خطای معنایی این است که کسی پیشنهاد می دهد "بیایید سه شنبه ملاقات کنیم" (بیایید سه شنبه ملاقات کنیم) و تشخیص دهنده می گوید "بیایید امروز ملاقات کنیم" (بیایید امروز ملاقات کنیم). در کلمات بدون اشتباه معنایی نیز اشتباهاتی وجود دارد. اگر تشخیص دهنده "up" را تشخیص نداد و برگشت "اجازه دهید سه شنبه ملاقات کنیم" ، معناشناسی جمله تغییر نکرد.
ما باید با دقت از تعداد کلمات اشتباه شناسایی شده ملاک استفاده کنیم. برای نشان دادن این ، من یک نمونه بدترین حالت را برای شما بیان می کنم. 5٪ خطاهای کلمه مربوط به یک کلمه گمشده از 20 است. اگر در هر جمله 20 کلمه وجود داشته باشد (که برای زبان انگلیسی کاملاً در حد متوسط است) ، تعداد جملات به اشتباه تشخیص داده شده به 100٪ می رسد. می توان امیدوار بود که کلمات به اشتباه تشخیص داده شده معنای معنایی جملات را تغییر ندهند. در غیر این صورت ، تشخیص دهنده می تواند به اشتباه هر جمله را رمزگشایی کند ، حتی با 5٪ تعداد کلمات به اشتباه تشخیص داده شده.
هنگام مقایسه مدل ها با افراد ، مهم است که ماهیت خطاها را بررسی کنید و نه تنها تعداد کلمات به اشتباه تشخیص داده شده را کنترل کنید. طبق تجربه من ، افرادی که گفتار را به متن ترجمه می کنند کمتر اشتباه می کنند و به اندازه کامپیوتر جدی نیستند.
محققان مایکروسافت اخیراً خطاهای انسانی را با دستگاه های شناسایی رایانه در سطح مشابه مقایسه کردند. یکی از تفاوتهای یافت شده این است که این مدل "uh" [uh-uh ...] را با "uh huh" [aha] خیلی بیشتر از مردم اشتباه می گیرد. این دو اصطلاح معنایی بسیار متفاوتی دارند: "اوه" مکث ها را پر می کند ، و "اوه تو" نشان دهنده تأیید شنونده است. همچنین ، انواع مختلفی از خطاها در مدل ها و افراد مشاهده شد.
صداهای زیادی در یک کانال
شناخت مکالمات تلفنی ضبط شده نیز آسان تر است زیرا هر بلندگو روی میکروفون جداگانه ضبط شده است. هیچ تداخل چند صدا در یک کانال صوتی وجود ندارد. مردم می توانند چندین سخنران را درک کنند ، گاهی اوقات همزمان صحبت می کنند.یک تشخیص دهنده گفتار خوب باید بتواند جریان صوتی را به بلندگو بسته به بلندگو تقسیم کند (آن را به صورت روزانه درآورید). او همچنین باید ضبط صوتی را با دو صدای همپوشانی (تفکیک منبع) معنا کند. این کار باید بدون میکروفون مستقر در دهان هر بلندگو انجام شود ، به این معنی که هنگام قرار گرفتن در مکان دلخواه ، تشخیص دهنده به خوبی کار کند.
ضبط کیفیت
لهجه ها و سر و صدای پس زمینه فقط دو عاملی است که یک تشخیص دهنده گفتار باید در برابر آنها مقاومت کند. در اینجا چند مورد دیگر آورده شده است:Reverb در شرایط مختلف صوتی.
مصنوعات مربوط به تجهیزات.
مصنوعات کدک مورد استفاده برای ضبط و فشرده سازی سیگنال.
فرکانس نمونه برداری.
سن گوینده
اکثر مردم نمی توانند فایل های mp3 و wav را از طریق گوش تشخیص دهند. دستگاه های شناسایی قبل از ادعای عملکردی مانند انسان باید در برابر منابع تنوع ذکر شده مقاوم باشند.
متن نوشته
می بینید که تعداد اشتباهاتی که مردم در تست های مربوط به سوابق تلفن از دست می دهند بسیار زیاد است. اگر با دوستی صحبت می کردید که از هر 20 کلمه 1 کلمه را نمی فهمید ، برقراری ارتباط برای شما بسیار دشوار است.یکی از دلایل این امر شناخت بدون توجه به زمینه است. در زندگی واقعی ، ما از ویژگی های اضافی مختلف و مختلفی برای کمک به ما در درک صحبت های طرف مقابل استفاده می کنیم. چند نمونه از متن مورد استفاده انسان و نادیده گرفته شده توسط تشخیص دهنده گفتار:
تاریخچه مکالمه و موضوع مورد بحث.
نشانه های دیداری درباره گوینده - حالات صورت ، حرکات لب.
مجموعه دانش درباره شخصی که با او صحبت می کنیم.
اکنون ضبط کننده گفتار Android لیستی از مخاطبین شما در اختیار شما قرار داده است ، بنابراین می تواند نام دوستان شما را تشخیص دهد. جستجوی صوتی در نقشه ها از موقعیت جغرافیایی برای محدود کردن گزینه هایی که می خواهید به آنجا بروید استفاده می کند.
دقت سیستم های تشخیص با درج چنین سیگنال هایی در داده ها افزایش می یابد. اما ما در حال شروع به بررسی عمیق تری در نوع زمینه ای هستیم که ممکن است در پردازش و نحوه استفاده از آن بگنجانیم.
گسترش
پیشرفت های اخیر در تشخیص گفتار محاوره ای غیرممکن است که گسترش یابد. هنگام تصور استفاده از الگوریتم تشخیص گفتار ، باید تأخیر و قدرت محاسبه را در ذهن داشته باشید. این پارامترها مرتبط هستند زیرا الگوریتم هایی که نیازهای برق را افزایش می دهند ، تأخیر را نیز افزایش می دهند. اما به منظور سادگی ، ما جداگانه در مورد آنها بحث خواهیم کرد.تأخیر: زمان پایان صحبت کاربر تا پایان دریافت رونویسی. تأخیر کم یک نیاز معمول برای تشخیص است. این تا حد زیادی بر تجربه کاربر با محصول تأثیر می گذارد. محدودیتی از دهها میلی ثانیه اغلب مشاهده می شود. این ممکن است کمی طاقت فرسا به نظر برسد ، اما به یاد داشته باشید که صدور رمزگشایی معمولاً اولین مرحله از یک سری محاسبات پیچیده است. به عنوان مثال ، در مورد جستجوی صوتی در اینترنت ، پس از تشخیص گفتار ، شما هنوز هم نیاز به وقت برای انجام جستجو دارید.
لایه های دو طرفه دو طرفه یک نمونه معمولی از بهبود است که تأخیر را بدتر می کند. آخرین نتایج رمزگشایی با کیفیت بالا با کمک آنها بدست می آید. تنها مشکل این است که ما نمی توانیم پس از عبور از لایه دو طرفه اول ، چیزی را حساب کنیم تا زمانی که فرد صحبت خود را تمام کند. بنابراین ، تاخیر با طولانی شدن حکم افزایش می یابد.
چپ: عود رو به جلو اجازه می دهد تا رمزگشایی بلافاصله آغاز شود. راست: تکرار دو طرفه مستلزم آن است که قبل از شروع رمزگشایی منتظر پایان سخنرانی باشید.
یک روش خوب برای استفاده موثر از اطلاعات آینده در تشخیص گفتار هنوز به دنبال آن است.
توان محاسباتی: این پارامتر تحت تأثیر محدودیت های اقتصادی است. هزینه ضیافت باید برای هر بهبود در دقت تشخیص دهنده در نظر گرفته شود. اگر بهبود به آستانه اقتصادی نرسد ، از بروز خارج می شود.
یک مثال کلاسیک از بهبود مستمر که هرگز استفاده نمی شود ، یادگیری عمیق مشارکتی است. کاهش 1-2 درصدی خطاها به ندرت افزایش 2-8 برابر قدرت محاسباتی را توجیه می کند. مدل های مدرن شبکه های راجعه نیز در این دسته قرار می گیرند ، زیرا استفاده از آنها در جستجوی مجموعه ای از مسیرها بسیار بی فایده است ، گرچه ، فکر می کنم ، وضعیت در آینده تغییر خواهد کرد.
می خواهم روشن کنم - نمی گویم که بهبود دقت تشخیص با افزایش جدی هزینه های محاسباتی بی فایده است. ما قبلاً دیدیم که چگونه اصل "ابتدا به آرامی اما مطمئناً سپس سریع" در گذشته کار می کند. نکته این است که تا زمانی که پیشرفت به اندازه کافی سریع نباشد ، نمی توان از آن استفاده کرد.
در پنج سال آینده
هنوز بسیاری از مشکلات حل نشده و پیچیده در زمینه تشخیص گفتار وجود دارد. در میان آنها:گسترش قابلیت های سیستم های ذخیره سازی داده های جدید ، تشخیص لهجه ها ، گفتار در برابر پس زمینه نویز شدید.
از جمله زمینه در فرآیند شناسایی.
دیاریزاسیون و تفکیک منابع.
تعداد خطاهای معنایی و روش های ابتکاری برای ارزیابی تشخیص دهنده ها.
تأخیر بسیار کم.
من منتظر پیشرفتی هستم که طی پنج سال آینده در این جبهه ها و سایر جبهه ها حاصل شود.
برچسب ها: افزودن برچسب ها
دوستان ، روز دیگر یکی از نوآوری هایی را که به روزرسانی Fall Creators برای ویندوز 10 آورده است ، بررسی کردیم - ... مایکروسافت قول پشتیبانی از ورودی صوتی را به زبان روسی در آینده می دهد ، اما مشخص نمی کند که این آینده نزدیک است یا دور. شاید زمانی باشد که کورتانا می تواند روسی صحبت کند و مهمتر از همه ، روسی را بفهمد. منتظر بمانید تا مایکروسافت به ویندوز 10 آموزش دهد تا درک کند ارزش ما نیست. اگر چیزی در محیط خود سیستم وجود نداشته باشد ، تقریباً همیشه می توان آن را با استفاده از ابزارهای نرم افزاری شخص ثالث پیاده سازی کرد. در واقع ، ما در این مقاله در مورد آنها صحبت خواهیم کرد. در زیر روش های مختلفی را بررسی خواهیم کرد که چگونه می توانید با استفاده از میکروفون تعبیه شده در لپ تاپ یا متصل به کامپیوتر ، اسناد جستجو را وارد کنید و متن اسناد را تعیین کنید.
1. "خوب ، آلیس" و جستجوی صوتی Google برای عبارت جستجو
مشخص نیست که چرا گوگل هنوز این فناوری را در رابط YouTube قرار نداده است. اما در هر صورت ، فیلم ها را می توان در موتور جستجو جستجو کرد ، و کلمات کلیدی را تلفظ می کند. سپس فقط باید به برگه "Video" در نتایج جستجو بروید. به دلایل واضح ، سهم شیر از نتایج جستجو همچنان از YouTube خواهد بود.
کسانی که قبلاً موفق به آشنایی با آنها شده اند - و نیازی به مراجعه به سایت موتور جستجو در پنجره مرورگر ندارند. پس از نصب برنامه ، قسمت جستجوی Yandex با قابلیت وارد کردن کوئری ها به صورت صوتی مستقیماً در نوار وظیفه ویندوز ظاهر می شود. و آلیس بدون ترک جعبه گفتگوی خود قادر خواهد بود بدون موتور جستجو به س questionsالات ساده نادر پاسخ دهد.
2. وب سرویس Web Speech API از Google
فناوری Web Speech API ، که از طریق آن ورودی صوتی درخواستها در موتور جستجوی Google پیاده سازی می شود ، دارای رابط وب خاص خود در:
https://www.google.com/intl/ja/chrome/demos/speech.html
عملکرد سرویس حداقل است: این شامل یک دکمه برای روشن کردن میکروفون و یک قسمت حاصل از آن است ، که در آن متن شناخته شده نمایش داده می شود.

اما هیچ ویرایشی در این زمینه حاصل نمی شود. در نتیجه ، نتایج شناخت را همانگونه که هستیم بدست خواهیم آورد. و می توانیم آنها را فقط در برخی ویرایشگرهای متن یا فرم ورود داده ویرایش کنیم. دکمه زیر قسمت "کپی و جایگذاری" حاصل ، جلسه ورودی فعلی را خاتمه می دهد و به طور خودکار یک بلوک انتخاب را روی کل متن شناخته شده قرار می دهد. این کار برای راحتی کپی کردن در کلیپ بورد انجام می شود.

برای متن شناخته شده ، یک ویژگی دیگر در دسترس است که توسط دکمه ایجاد ایمیل اجرا می شود. سرویس گیرنده نامه نصب شده در محیط ویندوز را به عنوان پیش فرض راه اندازی می کند ، پیام جدیدی ایجاد می کند و متن شناسایی شده را به آن منتقل می کند.
قابل توجه است که API گفتار وب می تواند برخی از علائم نگارشی ، حداقل یک دوره و یک ویرگول را تشخیص دهد. بنابراین در حین دیکته کردن ، می توانید آنها را به راحتی در مکان هایی که نقطه ها و ویرگول ها درج می شوند تلفظ کنید.
فقدان توانایی ویرایش متن در قسمت حاصل ، استفاده از Web Speech API را برای تایپ زیاد مناسب نمی کند. برای دستورات طولانی ، بهتر است از رابط وب سرویس Google Docs که در آن فناوری Web Speech API تعبیه شده است استفاده کنید. در Google Docs ، می توانید متن را به صورت صوتی وارد کنید ، و بلافاصله آن را ویرایش کنید ، و سند را در طول مسیر قالب بندی کنید.

3. "دفترچه یادداشت صوتی" در Speechpad.Ru
بر اساس فناوری Web Speech API ، یک وب سایت نیز وجود دارد - محبوب ترین و کاربردی ترین سرویس ورود اطلاعات صوتی در "دفترچه صوت" اینترنت روسیه. از جمله عملکردهای اصلی آن:
- پشتیبانی از چندین زبان ، از جمله روسی و اوکراینی.
- قسمت تشخیص صدا حاصل با قابلیت ویرایش متن ، ترجمه آن به زبانهای دیگر ، بارگذاری نتایج در یک فایل TXT.
- خروجی عبارات شناخته شده به کلیپ بورد ؛
- رونویسی
- ادغام در فرمهای وب مرورگرهای Chromium ؛
- ادغام در محیط ویندوز و لینوکس.
علاوه بر همه اینها ، در "صدای دفترچه یادداشت" گزینه ورودی صوتی فقط با فشار دادن دکمه مربوطه روشن و خاموش می شود. این گزینه به خودی خود غیرفعال نمی شود ، به محض اینکه مدتی در جستجوی عبارت دقیق فکر بیندیشیم ، همانطور که در سایر سرویس های مبتنی بر API گفتار وب اتفاق می افتد.


و متن شناسایی شده را در قسمت حاصل پیگیری می کنیم.
4. ادغام Speechpad در فرم های وب مرورگر

پس از اجرای این برنامه افزودنی ، مورد Speechpad در منوی زمینه فرم های وب برای وارد کردن متن ظاهر می شود. ما این دکمه را فشار می دهیم و با میکروفون صحبت می کنیم. بنابراین ، برای مثال ، می توانیم یادداشت ها را در Google Keep دیکته کنیم.


5. ادغام Speechpad در محیط ویندوز
قابلیت های وب سرویس Voice Notepad را می توان در محیط ویندوز ادغام کرد. و نوشتن متن به صورت صوتی در هر برنامه از سیستم عامل - یک دفترچه یادداشت معمولی ، Microsoft Word و ویرایشگرهای متن دیگر. گفتار شناخته شده بدون وساطت سرویس های وب یا کلیپ بورد مستقیماً در اسناد ویرایش شده جایگذاری می شود. با این حال ، چنین عملکرد Speechpad.Ru رایگان نیست و هزینه آن 100 روبل است. هر ماه. گزینه های پس انداز فراهم شده است: هنگام پرداخت فوری خدمات سه ماهه ، هزینه 250 روبل خواهد بود و پیش پرداخت سال 800 روبل هزینه دارد. هر کاربر ثبت شده ابتدا می تواند عملکرد سرویس را در محیط سیستم عامل خود ادغام کند. سازندگان Speechpad.Ru یک دوره آزمایشی دو روزه را به صورت رایگان ارائه می دهند. نحوه ادغام مستقیم دفترچه یادداشت صوتی در سیستم عامل ها ، به ویژه در ویندوز ، به طور مفصل در وب سایت Speechpad.Ru شرح داده شده است. روی علامت سوال کنار گزینه ادغام کلیک کنید.

و تمام مراحل شرح داده شده در دستورالعمل ها را طی می کنیم:
- افزونه خدمات فوق را نصب کنید ؛
- بارگیری بسته پرونده های ادغام ؛
- بایگانی را باز کنید و پرونده install_host.bat را اجرا کنید.
- در وب سایت Speechpad.Ru ، به حساب کاربر بروید ؛

ما دکمه "فعال کردن دوره آزمون" را فشار می دهیم.


و بنابراین هر بار که باید ورودی صوتی را فعال کنید. در واقع این همه است. اکنون می توانید Microsoft Word ، LibreOffice Writer ، ویرایشگرهای متن دیگر را باز کرده و دیکته را شروع کنید. متن شناسایی شده در پنجره هر برنامه فعال که از ورود داده پشتیبانی می کند ، ظاهر می شود.
مهم: برای استفاده از Speechpad در سیستم ، نمی توانید برگه وب سایت آن را در پنجره مرورگر ببندید. با بستن حالت دوم ، ورودی صدا غیرفعال می شود.
5. گزینه های رایگان برای ادغام ورودی صدا در محیط ویندوز
چه گزینه های رایگان برای ادغام ورود داده های صوتی روسی زبان در محیط ویندوز وجود دارد؟
گزینه شماره 1
در وب سایت Speechpad.Ru کاملا رایگان ، می توانید از گزینه خروجی گفتار شناسایی شده در کلیپ بورد استفاده کنید. ما دکمه "فعال کردن ضبط" را در سایت فشار می دهیم و به هر برنامه ویندوز منتقل می شویم.

اکنون می توانیم با استفاده از کلیدهای Ctrl + V عبارات را به صورت جداگانه تلفظ کرده و از کلیپ بورد جایگذاری کنیم. به محض مکث در سخنرانی ، صدای جیر جیر Speechpad را می شنویم که نشان می دهد این عبارت شناخته شده و در کلیپ بورد کپی شده است. این روش کار با ورودی صوتی مزایای خود را دارد: هنگام درج عبارات منفرد ، می توانید متن را به طور تمیز در طول مسیر ویرایش کنید.
گزینه شماره 2
برای کسانی که با برنامه های مجموعه آفیس کار می کنند ، مایکروسافت می تواند توسعه خود را برای پیاده سازی ورودی صوتی ارائه دهد - افزونه Dictate ، که یک برگه منوی اضافی را با یک ابزار تشخیص گفتار در Word ، Outlook و PowerPoint ادغام می کند. این افزودنی می تواند گفتار را به 20 زبان از جمله روسی تشخیص دهد و همزمان متن را به 60 زبان ترجمه کند.
روش رایگان دیگر برای وارد کردن متن از طریق صدا ، ضبط سخنرانی در یک فایل صوتی با رونویسی خودکار بیشتر است (رمزگشایی به متن). دور ، همه می توانند بلافاصله افکار خود را با یک زبان ادبی ساختار یافته بیان کنند ، و حتی در طول مسیر اشتباهات تشخیص صحیح ، علائم نگارشی را بگذارند. هنگام ضبط سخنرانی بر روی دیکتافون ، می توانید کاملاً بر محتوای مطالب ارائه شده تمرکز کنید و در مراحل رونویسی ، می توانید تمام تمرکز توجه خود را به فصاحت و سواد ارائه این مطالب معطوف کنید. اما دوستان ، اتوماسیون رونویسی از ضبط های صوتی موضوعی برای مقاله ای جداگانه است.
ادامه در مقالات: